


Exploitování – tvorba shellkódu 1. část
Vložil/a Juzna, 8 Leden, 2006 - 17:35
Exploitování je velice zajímavá činnost a existuje o něm hodně informací a dokonce sqělá kniha „Hacking – umění exploitace“. Ovšem většinou je vše popsané pro Linux. Pro vlastní pochopení exploitů to nevadí, ale informace jak napsat nějaký ten shellkód pro Win jsem snad žádné nenašel. Výsledkem bude shellkód který spustí příkazovou řádku a přemostí ji na libovolnou IP:port.
Exploitování
Uvědomte si, že hacker který chce cokoliv hacknout, musí být chytřejší než ten kdo daný program (nebo cokoliv) vytvářel. Hacker musí dokonale znát programovací jazyk, někdy i několik jazyků, a na dané problémy mít nadhled. Musí samotné příkazy chápat lépe než programátor, protože pak odhalí že programátor vlastně nenapsal přesně takový příkaz jaký chtěl. A toho náš hacker (zne)využije. Pokud jste ale nějaká lama co si umí přečíst emaily a chcete se nabourat do emailu někoho jiného, tak si radši vygooglete wwwhack.
Existuje mnoho různých exploitů podle toho co chcete exploitovat. Pokud chcete exploitovat webovou aplikaci psanou v PHP + mySQL, pak musíte znát tyto jazyky a třeba Assembler vám bude k ničemu. Ale na druhou stranu pokud chcete využít např. chyby v nějakém spustitelném programu a spustit tak svůj kód, budete muset umět assembler. Na tento způsob se dneska zaměříme.
Pokud se chcete dozvědět něco o technice a kráse exploitování, určitě si přečtěte knihu „Hacking – umění exploitace“. Z ní všechno pochopíte a nemá cenu ji zde přepisovat. Nebudu se zde zabývat jak udělat exploit a jak najít chybu v nějakém programu. I proto že to je hodně náročné a složité, a navíc autor určitě chybu brzo zaplátuje (pokud se nejedná o M$, který se se záplatama nijak nes... neuhání) a tak by vás jen naštvalo že se s tím tak hledáte. Ze začátku vám bude stačit najít si již nějaké bugy a pouze si upravit exploit, který už někdo vytvořil, aby dělal to co vy chcete. Osobně doporučuji třeba stránku www.frsirt.com kde najdete již bugů a exploitů hromadu.
Co potřebujeme?
• Assebmler - Pro vytvoření exploitu budeme potřebovat nějaký útržek programu, který šikovně dostaneme do zranitelného programu a pomocí chyby jej spustíme. Nejčastěji je psán v programovacím jazyce assebmler. Pokud jej neumíte, nezbývá vám nic než se jej naučit (doporučuji server www.manualy.sk a pokud se vám nechce hledat tady máte přímo odkaz na knihu o Asm: http://www.manualy.sk/koutek/volba9/).
• Kompilátor - já používám masm32, který si můžete vygooglit a zdarma stáhnout. Všechny příklady budou psány v něm, i když je můžete psát v jakémkoliv editoru a následně zkompilovat.
• Debugger – abychom se mohli přesvědčit že náš program funguje tak jak má, popřípadě pro hledání chyb, použijeme debugger. Pomocí něj můžeme krokovat jednotlivé příkazy a sledovat jak program probíhá. Já používám a doporučuji OllyDbg
• Zranitelný program – abych mohl zkoušet útržky kódu upravdu v praxi a jednoduše, udělal jsem si drobný prográmek ve Visual Basicu, který načte ze souboru náš program, umístí ho někam do paměti a následně zavolá. Můžete si jej stáhnout zde: www.juzna.com/vuln.php
Assembler
Potřebujeme napsat program, ze kterého použijeme jen jeho útržek (pouze samotný strojový kód). Tento útržek programu musí být úplně samostatný. Je to jako byste se objevili někde a nevíte kde. Nemáte sebou nic a o vše se musíte postarat sami. Pro náš kód to znamená, že je někde v paměti a nevíme kde jsou jakékoliv systémové funkce. Při psaní obyčejného programu v asm prostě naincludujeme knihovnu a pak voláme její funkce pomocí jména. Vůbec se nemusíme starat že je potřeba dané knihovny načíst a najít v nich funkce, to za nás udělá kompilátor. Nyní máme ale kus kódu vložený do jiného programu a musíme si vše obstarat sami.
První záchytný bod: kernell
Musíme postupovat od základních věcí co víme kde se dají najít a podle kterých pak můžeme hledat dále. Prvním záchytným bodem je pro nás knihovna kernell32.dll, kterou má načtenou každý program ve Win. Existuje více způsobů jaxe hledá. Nevím přesně jak který funguje, ale mě stačí že prostě fungují a je to. Pokud by se vám nelíbili nebo nefungovaly, můžete si nějaké zkusit vygooglit. Já jsem zatím narazil na 2 a oba zde popíšu.
První způsob nahodí do eax nějakou adresu kde často bývá knihovna kernell. Resp kernell je začíná někde před touto adresou. Proto postupně snižujeme eax a porovnáváme data co jsou na dané adrese. Jelikož všechny spustitelné programy začínají znaky MZ.., tak jakmile je najdeme, našli jsme kernell.
Ovšem neplatí to vždy. Je to řekl bych takový tipovací mechanizmus. Na SP1 mi fungoval vždycky na několika počítačích, ale na SP2 našel knihovnu GDI. Proto se lépe bude hodit jiné řešení:
Tento druhý kód mi funguje jak na SP1 tak na SP2. Bohužel nevím jak kernell najde, ale najde ho tak vždycky. Jeden příkaz mi nešel v masm přeložit, proto jsem ho nahradil přímo znaky které vzniknou po přeložení.
Nyní už tedy známe adresu na které se nachází v paměti knihovna kernell.
(Vlastní procedury a funkce si třeba umístěte až na konec kódu. Nebo je můžete dát na začátek, ale pak ještě před ně musíte vložit skok na vlastní kód)
Druhý záchytný bod: funkce GetProcAddress
Pomocí funkce GetProcAddress z knihovny kernell můžeme jednoduše najít adresy dalších potřebných funkcí. Nejdříve ale musíme najít tuto funkci „složitým“ způsobem.
Nejdříve voláním call skočíme na další instrukci, přičemž se na stack uloží návratová hodnota která ukazuje na instrukci za voláním, tzn. na náš string s názvem funkce kterou hledáme. Tuto adresu instrukcí pop uložíme do registru edx.
(ještě musím zmínit že při instrukcích skoku nebo volání je adresa kam se má skočit udávána relativně vzhledem k další instrukci. Takže instrukce volání bude ve stylu call +15 neboli skoč o na instrukci o 15 bajtů dál než je ta následující).
Dále si pomocí předchozí funkce najdeme adresu na kernell.
Pro další kroky je nutné vědět co v sobě skrývá klasická Windozácká knihovna, tudíž i kernell. Na daném místě v souboru je uložen offset na tzv. PE hlavičku. V ní je pak uložen offset na seznam exportovaných funkcí. Na tomto seznamu je uložen počet exportovaných funkcí a offset na seznam offsetů názvů těchto funkcí (dost složitá formulace, co?:)
Takže si ještě ujasněme co kde máme uloženo:
edx – adresa na náš string
ebx – adresa na kernell
ecx – počet exportovaných funkcí. Registr ecx je zvolen záměrně protože udává počet opakování při instrukci loop.
esi – adresa na ExportTable
edi – seznam offsetu na kterych jsou ulozeny nazvy funkci
stack – máme zde schovanou jeden registr, a to esi
Jdeme tedy procházet jednotlivé funkce a kontrolovat zda jejich název není GetProcAddress.
Nyní jsme v registru ebp získali index funkce, tzn. kolikátá fce z knihovny je ta naše. Zbývá nám složitou cestou vyhledat
Konečně jsme získali adresu na funkci GetProcAddr pomocí které získáme adresy na všechny další potřebné funkce.
Zkouška funkčnosti + debugging
Nyní bychom si mohli zkusit kód zkompilovat a následně spustit přes zranitelný program. Zjistíme tak zda program opravdu dělá to co jsme chtěli a zda jsme neudělali chybu. Pokud chyba nastala, zjistíme kde.
Na konec kódu přidáme ještě breakpoint, který nám zastaví v debuggeru abychom mohli vše zkontrolovat. Exploit zkompilujeme pomocí masm32 a přes program vuln spustíme. (celý zdroják si můžete stáhnout na www.juzna.com/sploit01.asm)
Pokud ovšem nebudeme daný program debuggovat, pak nám spadne (kvůli breakpointu) a Windows se nás zeptá jestli odeslat či neodeslat zprávu o havárii. Popřípadě pokud máte nainstalovaný a nastavený debugger tak vám umožní přímo vstup do debuggování tohoto programu.
Debugger
V debuggeru vidíme zvýrazněnou aktuální instrukci. Je to přerušení, na kterém se program zastavil a (pokud není již debuggován) neví jak dál a proto „spadne“.
V registru eax se má nacházet adresa na funkci GetProcAddress, což si můžeme ověřit vpravo nahoře když je podíváme na obsah registrů. Vedle eax vidíme jeji hodnotu 7C80AC28 a vedle toho popis, že se jedná o exportovanou funkci a její název.
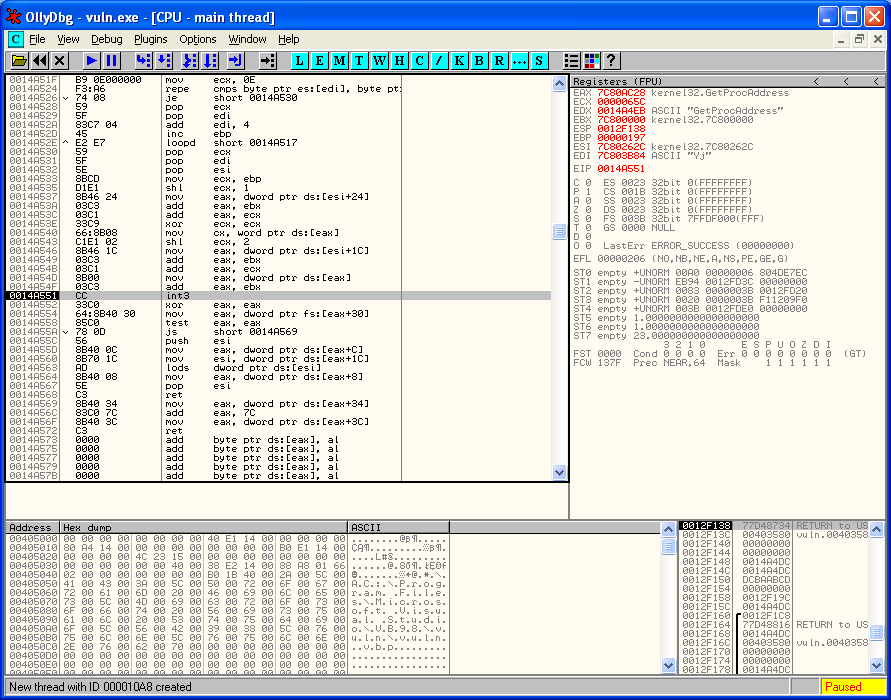
Vše je tedy zdá se v pořádku. Buď debugger ukončíme a s tím i zároveň náš spuštěný program, nebo můžeme zkusit pokračovat. Nevykonalo by se stejně ale nic rozumného, protože dál náš kód už nesahá.
Můžeme pokračovat v psaní kódu.
Související články:
Exploitování – tvorba shellkódu 2. část
Exploitování – tvorba shellkódu 3. část
- Pro psaní komentářů se přihlašte
